2 Python Language Basics, IPython, and Jupyter Notebooks
2.1 The Python Interpreter (Python 解释器)
Python 是一种解释型(interpreted)语言。Python 解释器通过一次执行一条语句来运行程序。可以使用 python 命令在命令行上调用标准交互式 Python 解释器:
$ python
Python 3.10.4 | packaged by conda-forge | (main, Mar 24 2022, 17:38:57)
[GCC 10.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> a = 5
>>> print(a)
5您看到的 >>> 是提示符,您可以在该提示符后键入代码表达式。要退出 Python 解释器,您可以键入 exit() 或按 Ctrl-D(仅适用于 Linux 和 macOS)。
运行 Python 程序就像使用 .py 文件作为第一个参数调用 python 一样简单。假设我们使用以下内容创建了 hello_world.py:
print("Hello world")您可以通过执行以下命令来运行它(hello_world.py 文件必须位于您当前的工作终端目录中):
$ python hello_world.py
Hello world虽然一些 Python 程序员以这种方式执行所有 Python 代码,但进行数据分析或科学计算的程序员则使用 IPython(一种增强的 Python 解释器)或 Jupyter notebooks(最初在 IPython 项目中创建的基于 Web 的代码笔记本)。我在本章中介绍了如何使用 IPython 和 Jupyter,并在 Appendix A: Advanced NumPy 中更深入地了解了 IPython 功能。当您使用 %run 命令时,IPython 会在同一进程中执行指定文件中的代码,使您能够在完成后以交互方式探索结果:
$ ipython
Python 3.10.4 | packaged by conda-forge | (main, Mar 24 2022, 17:38:57)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.31.1 -- An enhanced Interactive Python. Type '?' for help.
In [1]: %run hello_world.py
Hello world
In [2]:与标准的 >>> 提示符相比,默认的 IPython 提示符采用编号 In [2]: 样式。
2.2 IPython Basics
在本节中,我将帮助您启动并运行 IPython shell 和 Jupyter Notebook,并向您介绍一些基本概念。
2.2.1 Running the IPython Shell
您可以在命令行上启动 IPython shell,就像启动常规 Python 解释器一样,只不过使用 ipython 命令:
$ ipython
Python 3.10.4 | packaged by conda-forge | (main, Mar 24 2022, 17:38:57)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.31.1 -- An enhanced Interactive Python. Type '?' for help.
In [1]: a = 5
In [2]: a
Out[2]: 5您可以通过键入任意 Python 语句并按 Return(或 Enter)来执行它们。当您在 IPython 中键入一个变量时,它会呈现该对象的字符串表示形式:
In [5]: import numpy as np
In [6]: data = [np.random.standard_normal() for i in range(7)]
In [7]: data
Out[7]:
[-0.20470765948471295,
0.47894333805754824,
-0.5194387150567381,
-0.55573030434749,
1.9657805725027142,
1.3934058329729904,
0.09290787674371767]前两行是 Python 代码语句;第二条语句创建一个名为 data 的变量,该变量引用新创建的列表。最后一行在控制台中打印 data 的值。
许多类型的 Python 对象都被格式化为更具可读性或打印更美观,这与普通的 print 打印不同。如果你在标准 Python 解释器中打印上面的 data 变量,它的可读性会低得多:
>>> import numpy as np
>>> data = [np.random.standard_normal() for i in range(7)]
>>> print(data)
>>> data
[-0.5767699931966723, -0.1010317773535111, -1.7841005313329152,
-1.524392126408841, 0.22191374220117385, -1.9835710588082562,
-1.6081963964963528]IPython 还提供了执行任意代码块(通过某种美化的复制粘贴方法)和整个 Python 脚本的工具。您还可以使用 Jupyter notebook 来处理更大的代码块,我们很快就会看到。
2.2.2 Running the Jupyter Notebook
Jupyter 项目的主要组件之一是 notebook,一种用于代码、文本(包括 Markdown)、数据可视化和其他输出的交互式文档。Jupyter notebook 与 kernels 交互,kernels 是特定于不同编程语言的 Jupyter 交互式计算协议的实现。Python Jupyter kernel 使用 IPython 系统来实现其底层行为。
要启动 Jupyter,请在终端中运行命令 jupyter notebook:
$ jupyter notebook
[I 15:20:52.739 NotebookApp] Serving notebooks from local directory:
/home/wesm/code/pydata-book
[I 15:20:52.739 NotebookApp] 0 active kernels
[I 15:20:52.739 NotebookApp] The Jupyter Notebook is running at:
http://localhost:8888/?token=0a77b52fefe52ab83e3c35dff8de121e4bb443a63f2d...
[I 15:20:52.740 NotebookApp] Use Control-C to stop this server and shut down
all kernels (twice to skip confirmation).
Created new window in existing browser session.
To access the notebook, open this file in a browser:
file:///home/wesm/.local/share/jupyter/runtime/nbserver-185259-open.html
Or copy and paste one of these URLs:
http://localhost:8888/?token=0a77b52fefe52ab83e3c35dff8de121e4...
or http://127.0.0.1:8888/?token=0a77b52fefe52ab83e3c35dff8de121e4...在许多平台上,Jupyter 将自动在您的默认 Web 浏览器中打开(除非您使用 --no-browser 启动它)。否则,您可以导航到启动笔记本时打印的 HTTP 地址,此处为 http://localhost:8888/?token=0a77b52fefe52ab83e3c35dff8de121e4bb443a63f2d3055。请参阅 Figure 2.1 了解 Google Chrome 中的情况。
很多人使用 Jupyter 作为本地计算环境,但它也可以部署在服务器上并远程访问。我不会在这里介绍这些细节,但我鼓励您在互联网上探索这个主题(如果它与您的需求相关)。
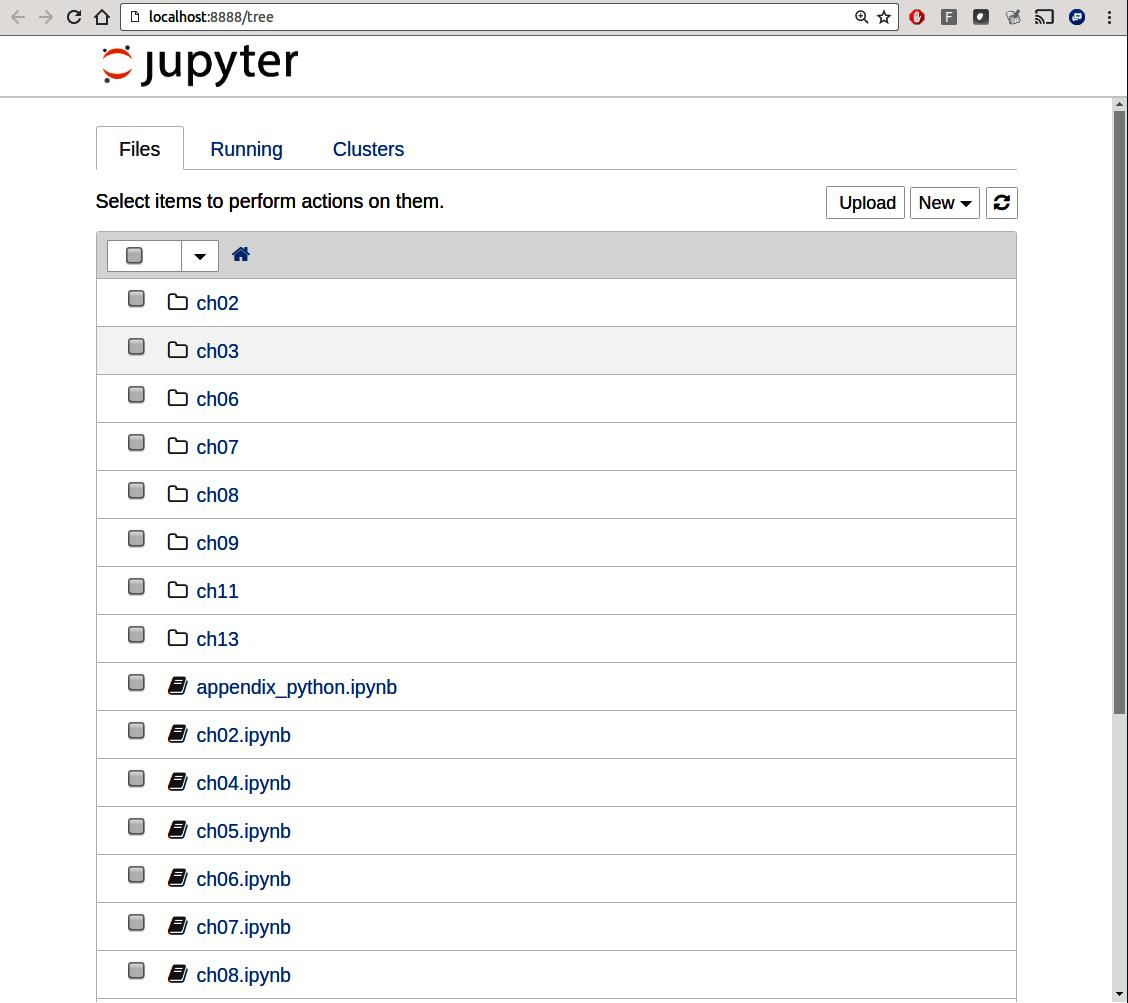
要创建新的笔记本,请单击“新建”按钮并选择“Python 3”选项。您应该看到如 Figure 2.2 所示的内容。如果这是您第一次,请尝试单击空代码“单元格”并输入一行 Python 代码。然后按 Shift-Enter 执行它。
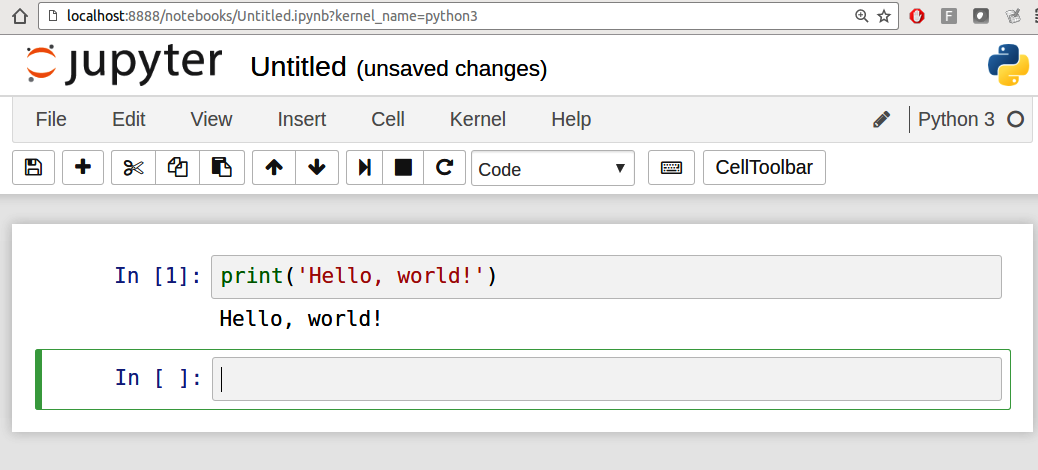
保存笔记本时(see “Save and Checkpoint” under the notebook File menu),它会创建一个扩展名为 .ipynb 的文件。这是一种独立的文件格式,包含当前笔记本中的所有内容(包括任何评估的代码输出)。其他 Jupyter 用户可以加载和编辑它们。
要重命名打开的笔记本,请单击页面顶部的笔记本标题并键入新标题,完成后按 Enter。
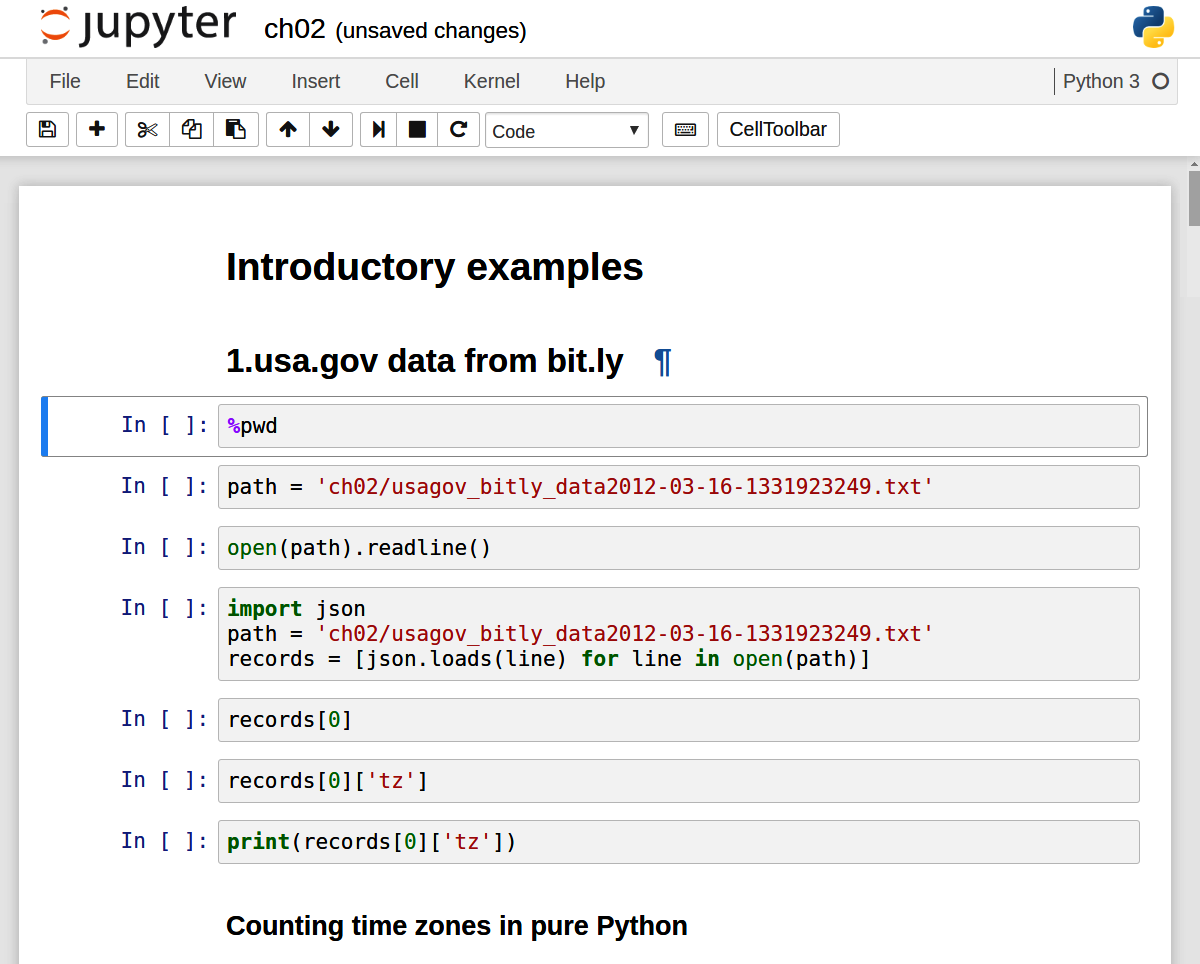
要加载现有笔记本,请将文件放在启动笔记本进程的同一目录中(或其中的子文件夹中),然后单击登录页面中的名称。您可以使用我在 GitHub 上的 wesm/pydata-book 存储库中的笔记本进行尝试。参见 Figure 2.3。
当您想要关闭笔记本时,请单击 File 菜单并选择 “Close and Halt”。如果您只是关闭浏览器选项卡,与笔记本关联的 Python 进程将继续在后台运行。
虽然 Jupyter Notebook 可能给人一种与 IPython shell 截然不同的体验,但本章中的几乎所有命令和工具都可以在任一环境中使用。
2.2.3 Tab Completion
从表面上看,IPython shell 看起来像是标准终端 Python 解释器(使用 python 调用)的一个外观上不同的版本。相对于标准 Python shell 的主要改进之一是制表符补全,在许多 IDEs 或其他交互式计算分析环境中都可以找到。在 shell 中输入表达式时,按 Tab 键将在命名空间中搜索与您目前键入的字符相匹配的任何变量(对象、函数等),并在方便的下拉菜单中显示结果:
In [1]: an_apple = 27
In [2]: an_example = 42
In [3]: an<Tab>
an_apple an_example any在此示例中,请注意 IPython 显示了我定义的两个变量以及内置函数 any。此外,您还可以在输入句点后完成任何对象的方法和属性:
In [3]: b = [1, 2, 3]
In [4]: b.<Tab>
append() count() insert() reverse()
clear() extend() pop() sort()
copy() index() remove()对于模块也是如此:
In [1]: import datetime
In [2]: datetime.<Tab>
date MAXYEAR timedelta
datetime MINYEAR timezone
datetime_CAPI time tzinfo请注意,IPython 默认隐藏以下划线开头的方法和属性,例如 magic 方法和内部“私有(private)”方法和属性,以避免显示混乱(并使新手用户感到困惑!)。这些也可以通过制表符完成,但您必须首先键入下划线才能看到它们。如果您希望始终在制表符补全中看到此类方法,则可以在 IPython 配置中更改此设置。请参阅 IPython documentation 以了解如何执行此操作。
除了搜索交互式命名空间和完成对象或模块属性之外,选项卡补全还可以在许多上下文中使用。当输入任何看起来像文件路径的内容时(即使是 Python 字符串),按 Tab 键将完成计算机文件系统上与您输入的内容匹配的任何内容。
与 %run 命令(请参阅 Appendix B.2.1: The %run Command)结合使用,此功能可以节省您许多击键次数。
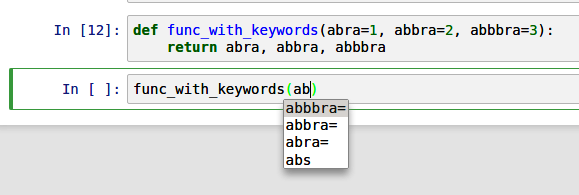
制表符补全可以节省时间的另一个方面是函数关键字参数的补全(包括 = 符号!)。参见 Figure 2.4。
稍后我们将更仔细地了解函数。
2.2.4 Introspection
在变量之前或之后使用问号 (?) 将显示有关该对象的一些常规信息:
In [1]: b = [1, 2, 3]
In [2]: b?
Type: list
String form: [1, 2, 3]
Length: 3
Docstring:
Built-in mutable sequence.
If no argument is given, the constructor creates a new empty list.
The argument must be an iterable if specified.
In [3]: print?
Docstring:
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly flush the stream.
Type: builtin_function_or_method这称为对象自省(introspection)。如果对象是函数或实例方法,则还将显示文档字符串(如果已定义)。假设我们编写了以下函数(您可以在 IPython 或 Jupyter 中重现):
def add_numbers(a, b):
"""
Add two numbers together
Returns
-------
the_sum : type of arguments
"""
return a + b然后使用 ? 向我们展示了文档字符串:
In [6]: add_numbers?
Signature: add_numbers(a, b)
Docstring:
Add two numbers together
Returns
-------
the_sum : type of arguments
File: <ipython-input-9-6a548a216e27>
Type: function?还有最后一个用途,即以类似于标准 Unix 或 Windows 命令行的方式搜索 IPython 命名空间。多个字符与通配符 (*) 组合将显示与通配符表达式匹配的所有名称。例如,我们可以获得顶级 NumPy 命名空间中包含 load 的所有函数的列表:
In [9]: import numpy as np
In [10]: np.*load*?
np.__loader__
np.load
np.loads
np.loadtxt2.3 Python Language Basics
在本节中,我将概述基本的 Python 编程概念和语言机制。在下一章中,我将更详细地介绍 Python 数据结构、函数和其他内置工具。
2.3.1 Language Semantics
Python 语言设计的特点是强调可读性、简单性和明确性。有些人甚至将其比作“可执行伪代码(executable pseudocode)”。
Indentation, not braces(缩进,而不是大括号)
Python 使用空格(制表符或空格)来构建代码,而不是像 R、C++、Java 和 Perl 等许多其他语言那样使用大括号。考虑排序算法中的 for 循环:
for x in array:
if x < pivot:
less.append(x)
else:
greater.append(x)冒号表示缩进代码块的开始,之后所有代码都必须缩进相同的量,直到块的末尾。
不管你喜欢还是讨厌,重要的空格对于 Python 程序员来说都是一个事实。虽然一开始它可能看起来很陌生,但希望您很快就会习惯它。
我强烈建议使用四个空格作为默认缩进,并将制表符替换为四个空格。许多文本编辑器都有一个设置,可以自动用空格替换制表位(这样做!)。IPython 和 Jupyter notebooks 将自动在冒号后面的新行中插入四个空格,并将制表符替换为四个空格。
正如您现在所看到的,Python 语句也不需要以分号终止。但是,可以使用分号来分隔一行上的多个语句:
a = 5; b = 6; c = 7在 Python 中通常不鼓励将多个语句放在一行上,因为这会降低代码的可读性。
Everything is an object(一切皆对象)
Python 语言的一个重要特性是其对象模型的一致性。每个数字、字符串、数据结构、函数、类、模块等都存在于 Python 解释器中自己的“盒子”中,称为 Python object。每个对象都有一个关联的类型(例如整数、字符串或函数)和内部数据。实际上,这使得该语言非常灵活,因为甚至函数也可以像任何其他对象一样对待。
Comments(注释)
Python 解释器会忽略任何以井号 # 开头的文本。这通常用于向代码添加注释。有时您可能还想排除某些代码块而不删除它们。一种解决方案是注释掉代码:
results = []
for line in file_handle:
# keep the empty lines for now
# if len(line) == 0:
# continue
results.append(line.replace("foo", "bar"))注释也可以出现在执行代码行之后。虽然有些程序员喜欢将注释放在特定代码行的前面,但这有时很有用:
print("Reached this line") # Simple status reportFunction and object method calls(函数和对象方法调用)
您可以使用括号并传递零个或多个参数来调用函数,还可以选择将返回值分配给变量:
result = f(x, y, z)
g()Python 中几乎每个对象都具有附加函数(称为方法),可以访问对象的内部内容。您可以使用以下语法来调用它们:
obj.some_method(x, y, z)函数可以同时采用位置参数和关键字参数:
result = f(a, b, c, d=5, e="foo")稍后我们将更详细地讨论这一点。
Variables and argument passing(变量和参数传递)
在 Python 中分配变量(或名称)时,您正在创建对等号右侧显示的对象的引用。实际上,考虑一个整数列表:
In [8]: a = [1, 2, 3]假设我们将 a 赋给一个新变量 b:
In [9]: b = a
In [10]: b
Out[10]: [1, 2, 3]在某些语言中,如果 b 的赋值会导致数据 [1, 2, 3] 被复制。在 Python 中,a 和 b 现在实际上指的是同一个对象,即原始列表 [1, 2, 3](参见 Figure 2.5 的模型)。您可以通过将一个元素附加到 a 然后检查 b 来向自己证明这一点:
In [11]: a.append(4)
In [12]: b
Out[12]: [1, 2, 3, 4]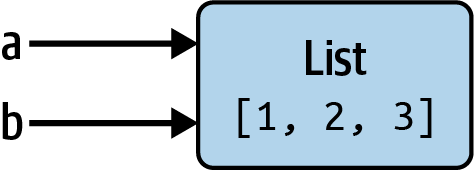
当您在 Python 中处理较大的数据集时,了解 Python 中引用的语义以及复制数据的时间、方式和原因尤其重要。
赋值(Assignment)也称为绑定(binding),因为我们将名称绑定到对象。已分配的变量名称有时可能称为绑定变量。
当您将对象作为参数传递给函数时,将创建引用原始对象的新局部变量,而不进行任何复制。如果将新对象绑定到函数内部的变量,则不会覆盖函数外部“范围(scope)”(“父范围(parent scope)”)中的同名变量。因此,可以改变可变参数的内部结构。假设我们有以下函数:
In [13]: def append_element(some_list, element):
....: some_list.append(element)然后我们有:
In [14]: data = [1, 2, 3]
In [15]: append_element(data, 4)
In [16]: data
Out[16]: [1, 2, 3, 4]Dynamic references, strong types(动态引用、强类型)
Python 中的变量没有与其关联的固有类型;只需进行赋值,变量就可以引用不同类型的对象。以下情况是没有问题的:
In [17]: a = 5
In [18]: type(a)
Out[18]: int
In [19]: a = "foo"
In [20]: type(a)
Out[20]: str变量是特定命名空间中对象的名称;类型信息存储在对象本身中。一些观察者可能会仓促得出结论:Python 不是一种“类型化语言”。这不是真的;考虑这个例子:
In [21]: "5" + 5
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-21-7fe5aa79f268> in <module>
----> 1 "5" + 5
TypeError: can only concatenate str (not "int") to str在某些语言中,字符串 '5' 可能会隐式转换为整数,从而生成 10。在其他语言中,整数 5 可能会转换为字符串,生成连接字符串 '55'。在 Python 中,不允许这种隐式转换。就此而言,我们说 Python 是一种强类型(strongly typed)语言,这意味着每个对象都有特定的类型(或类),并且只有在某些允许的情况下才会发生隐式转换,例如:
In [22]: a = 4.5
In [23]: b = 2
# String formatting, to be visited later
In [24]: print(f"a is {type(a)}, b is {type(b)}")
a is <class 'float'>, b is <class 'int'>
In [25]: a / b
Out[25]: 2.25这里,即使 b 是整数,它也会被隐式转换为浮点数以进行除法运算。
了解对象的类型很重要,并且能够编写可以处理多种不同类型输入的函数非常有用。您可以使用 isinstance 函数检查对象是否是特定类型的实例:
In [26]: a = 5
In [27]: isinstance(a, int)
Out[27]: True如果您想检查对象的类型是否属于元组中存在的类型,则 isinstance 可以接受类型元组:
In [28]: a = 5; b = 4.5
In [29]: isinstance(a, (int, float))
Out[29]: True
In [30]: isinstance(b, (int, float))
Out[30]: TrueAttributes and methods(属性和方法)
Python 中的对象通常具有属性(存储在对象“内部”的其他 Python 对象)和方法(与对象关联的可以访问对象内部数据的函数)。它们都可以通过语法 <obj.attribute_name> 访问:
In [1]: a = "foo"
In [2]: a.<Press Tab>
capitalize() index() isspace() removesuffix() startswith()
casefold() isprintable() istitle() replace() strip()
center() isalnum() isupper() rfind() swapcase()
count() isalpha() join() rindex() title()
encode() isascii() ljust() rjust() translate()
endswith() isdecimal() lower() rpartition()
expandtabs() isdigit() lstrip() rsplit()
find() isidentifier() maketrans() rstrip()
format() islower() partition() split()
format_map() isnumeric() removeprefix() splitlines()属性和方法也可以通过 getattr 函数按名称访问:
In [32]: getattr(a, "split")
Out[32]: <function str.split(sep=None, maxsplit=-1)>虽然我们不会在本书中广泛使用函数 getattr 以及相关函数 hasattr 和 setattr,但它们可以非常有效地用于编写通用的、可重用的代码。
Duck typing(鸭子类型)
通常,您可能不关心对象的类型,而只关心它是否具有某些方法或行为。这有时被称为鸭子类型,俗话说“如果它像鸭子一样行走并且像鸭子一样嘎嘎叫,那么它就是一只鸭子”。例如,如果一个对象实现了迭代器协议(iterator protocol),您可以验证该对象是否可迭代。对于许多对象来说,这意味着它有一个 __iter__ “魔术方法(magic method)”,尽管另一种更好的检查方法是尝试使用 iter 函数:
In [33]: def isiterable(obj):
....: try:
....: iter(obj)
....: return True
....: except TypeError: # not iterable
....: return False对于字符串以及大多数 Python 集合类型,此函数将返回 True:
In [34]: isiterable("a string")
Out[34]: True
In [35]: isiterable([1, 2, 3])
Out[35]: True
In [36]: isiterable(5)
Out[36]: FalseImports
在 Python 中,模块只是一个包含 Python 代码、扩展名为 .py 的文件。假设我们有以下模块:
# some_module.py
PI = 3.14159
def f(x):
return x + 2
def g(a, b):
return a + b如果我们想从同一目录中的另一个文件访问 some_module.py 中定义的变量和函数,我们可以这样做:
import some_module
result = some_module.f(5)
pi = some_module.PI或者:
from some_module import g, PI
result = g(5, PI)通过使用 as 关键字,您可以为导入指定不同的变量名称:
import some_module as sm
from some_module import PI as pi, g as gf
r1 = sm.f(pi)
r2 = gf(6, pi)Binary operators and comparisons(二元运算符和比较)
大多数二元数学运算和比较都使用其他编程语言中使用的熟悉的数学语法:
In [37]: 5 - 7
Out[37]: -2
In [38]: 12 + 21.5
Out[38]: 33.5
In [39]: 5 <= 2
Out[39]: False有关所有可用的二元运算符,请参阅 Table 2.1。
| Operation | Description |
|---|---|
a + b |
a 加 b |
a - b |
a 减 b |
a * b |
a 乘 b |
a / b |
a 除 b |
a // b |
a 除 b 后取整 |
a ** b |
a 的 b 次方 |
a & b |
如果 a 和 b 都为 True,则为 True;对于整数,采用按位 AND |
a | b |
如果 a 或 b 为 True,则为 True;对于整数,采用按位 OR |
a ^ b |
对于布尔值,如果 a 或 b 为 True,但不是两者都为 True,则为 True;对于整数,采用按位 EXCLUSIVE-OR |
a == b |
如果 a 等于 b,则为 True |
a != b |
如果 a 不等于 b,则为 True |
a < b, a <= b |
如果 a 小于(小于或等于)b,则为 True |
a > b, a >= b |
如果 a 大于(大于或等于)b,则为 True |
a is b |
如果 a 和 b 引用同一个 Python 对象,则为 True |
a is not b |
如果 a 和 b 引用不同的 Python 对象,则为 True |
要检查两个变量是否引用同一个对象,请使用 is 关键字。使用 is not 检查两个对象是否不相同:
In [40]: a = [1, 2, 3]
In [41]: b = a
In [42]: c = list(a)
In [43]: a is b
Out[43]: True
In [44]: a is not c
Out[44]: True由于 list 函数总是创建一个新的 Python 列表(即副本),因此我们可以确定 c 与 a 不同。使用 is 进行比较与 == 运算符不同,因为在这种情况下我们有:
In [45]: a == c
Out[45]: Trueis 和 is not 的一种常见用途是检查变量是否为 None,因为 None 仅有一个实例:
In [46]: a = None
In [47]: a is None
Out[47]: TrueMutable and immutable objects(可变和不可变对象)
Python 中的许多对象,例如列表、字典、NumPy 数组和大多数用户定义的类型(类),都是可变的。这意味着可以修改它们包含的对象或值:
In [48]: a_list = ["foo", 2, [4, 5]]
In [49]: a_list[2] = (3, 4)
In [50]: a_list
Out[50]: ['foo', 2, (3, 4)]其他的,如字符串和元组,是不可变的,这意味着它们的内部数据不能更改:
In [51]: a_tuple = (3, 5, (4, 5))
In [52]: a_tuple[1] = "four"
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-52-cd2a018a7529> in <module>
----> 1 a_tuple[1] = "four"
TypeError: 'tuple' object does not support item assignment请记住,仅仅因为您可以改变对象并不意味着您总是应该这样做。此类行为称为副作用。例如,在编写函数时,应在函数的文档或注释中明确向用户传达任何副作用。如果可能的话,我建议尝试避免副作用并支持不变性,即使可能涉及可变对象。
2.3.2 Scalar Types
Python 有一小部分内置类型用于处理数值数据、字符串、布尔值(True 或 False)以及日期和时间。这些“单值(single value)”类型有时称为标量类型(scalar types),我们在本书中将它们称为标量(scalars)。有关主要标量类型的列表,请参阅 Table 2.2。日期和时间处理将单独讨论,因为它们是由标准库中的 datetime 模块提供的。
| Type | Description |
|---|---|
None |
Python “null” 值(None 对象仅存在一个实例) |
str |
字符串类型;保存 Unicode 字符串 |
bytes |
原始二进制数据 |
float |
双精度浮点数(注意没有单独的 double 类型) |
bool |
布尔 True 或 False 值 |
int |
任意精度整数 |
Numeric types
Python 中数字的主要类型是 int 和 float。int 可以存储任意大的数字:
In [53]: ival = 17239871
In [54]: ival ** 6
Out[54]: 26254519291092456596965462913230729701102721浮点数用 Python float 类型表示。在底层,每一个都是一个双精度值。它们也可以用科学计数法来表示:
In [55]: fval = 7.243
In [56]: fval2 = 6.78e-5不产生整数的整数除法将始终产生浮点数:
In [57]: 3 / 2
Out[57]: 1.5要获得 C-style 的整数除法(如果结果不是整数,则舍去小数部分),请使用向下取整除法运算符 //:
In [58]: 3 // 2
Out[58]: 1Strings
许多人使用 Python 是因为它内置的字符串处理功能。您可以使用单引号 ' 或双引号 " 编写字符串文字(通常首选双引号):
a = 'one way of writing a string'
b = "another way"Python 的字符串类型是 str。
对于带有换行符的多行字符串,您可以使用三引号,即 ''' 或 """:
c = """
This is a longer string that
spans multiple lines
"""您可能会惊讶这个字符串 c 实际上包含四行文本; """ 之后的换行符和 lines 之后都包含在字符串中。我们可以使用 c 上的 count 方法来计算新行字符:
In [60]: c.count("\n")
Out[60]: 3Python 字符串是不可变的;你不能修改字符串:
In [61]: a = "this is a string"
In [62]: a[10] = "f"
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-62-3b2d95f10db4> in <module>
----> 1 a[10] = "f"
TypeError: 'str' object does not support item assignment要解释此错误消息,请从下往上阅读。我们尝试将位置 10 处的字符(“item”)替换为字母"f",但这对于字符串对象是不允许的。如果我们需要修改字符串,我们必须使用创建新字符串的函数或方法,例如字符串 replace 方法:
In [63]: b = a.replace("string", "longer string")
In [64]: b
Out[64]: 'this is a longer string'执行此操作后,变量 a 未修改:
In [65]: a
Out[65]: 'this is a string'许多 Python 对象可以使用 str 函数转换为字符串:
In [66]: a = 5.6
In [67]: s = str(a)
In [68]: print(s)
5.6字符串是 Unicode 字符序列,因此可以像其他序列(例如列表和元组)一样对待:
In [69]: s = "python"
In [70]: list(s)
Out[70]: ['p', 'y', 't', 'h', 'o', 'n']
In [71]: s[:3]
Out[71]: 'pyt'语法 s[:3] 称为切片(slicing),并为多种 Python 序列实现。稍后将对此进行更详细的解释,因为它在本书中被广泛使用。
反斜杠字符 \ 是转义字符,这意味着它用于指定特殊字符,例如换行符 \n 或 Unicode 字符。要编写带有反斜杠的字符串文字,您需要对它们进行转义:
In [72]: s = "12\\34"
In [73]: print(s)
12\34如果您的字符串包含很多反斜杠并且没有特殊字符,您可能会发现这有点烦人。幸运的是,您可以在字符串的前导引号前添加 r,这意味着字符应按原样解释:
In [74]: s = r"this\has\no\special\characters"
In [75]: s
Out[75]: 'this\\has\\no\\special\\characters'r 代表原始(raw)。
将两个字符串相加会将它们连接起来并生成一个新字符串:
In [76]: a = "this is the first half "
In [77]: b = "and this is the second half"
In [78]: a + b
Out[78]: 'this is the first half and this is the second half'字符串模板或格式化是另一个重要主题。随着 Python 3 的出现,实现此目的的方法数量不断增加,在这里我将简要描述其中一个主要接口的机制。字符串对象有一个 format 方法,可用于将格式化参数替换为字符串,生成一个新字符串:
In [79]: template = "{0:.2f} {1:s} are worth US${2:d}"在这个字符串中:
{0:.2f}表示将第一个参数格式化为具有两位小数的浮点数。{1:s}表示将第二个参数格式化为字符串。{2:d}表示将第三个参数格式化为精确整数。
为了替换这些格式参数的参数,我们将一系列参数传递给 format 方法:
In [80]: template.format(88.46, "Argentine Pesos", 1)
Out[80]: '88.46 Argentine Pesos are worth US$1'Python 3.6 引入了一个名为 f-strings(格式化字符串文字的缩写)的新功能,它可以使创建格式化字符串变得更加方便。要创建 f-strings,请在字符串文字前面写入字符 f。在字符串中,将 Python 表达式括在大括号中,以将表达式的值替换为格式化字符串:
In [81]: amount = 10
In [82]: rate = 88.46
In [83]: currency = "Pesos"
In [84]: result = f"{amount} {currency} is worth US${amount / rate}"可以使用与上面的字符串模板相同的语法在每个表达式之后添加格式说明符:
In [85]: f"{amount} {currency} is worth US${amount / rate:.2f}"
Out[85]: '10 Pesos is worth US$0.11'字符串格式化是一个深奥的话题;有多种方法和大量选项和调整可用于控制结果字符串中值的格式。要了解更多信息,请查阅 official Python documentation。
Bytes and Unicode
在现代 Python(即 Python 3.0 及更高版本)中,Unicode 已成为一流的字符串类型,可以更一致地处理 ASCII 和 non-ASCII 文本。在旧版本的 Python 中,字符串都是字节,没有任何显式的 Unicode 编码。假设您知道字符编码,则可以转换为 Unicode。下面是一个包含非 ASCII 字符的 Unicode 字符串示例:
In [86]: val = "español"
In [87]: val
Out[87]: 'español'我们可以使用 encode 方法将此 Unicode 字符串转换为其 UTF-8 字节表示形式:
In [88]: val_utf8 = val.encode("utf-8")
In [89]: val_utf8
Out[89]: b'espa\xc3\xb1ol'
In [90]: type(val_utf8)
Out[90]: bytes假设您知道 bytes 对象的 Unicode 编码,您可以使用 decode 方法返回:
In [91]: val_utf8.decode("utf-8")
Out[91]: 'español'虽然现在最好对任何编码使用 UTF-8,但由于历史原因,您可能会遇到多种不同编码的数据:
In [92]: val.encode("latin1")
Out[92]: b'espa\xf1ol'
In [93]: val.encode("utf-16")
Out[93]: b'\xff\xfee\x00s\x00p\x00a\x00\xf1\x00o\x00l\x00'
In [94]: val.encode("utf-16le")
Out[94]: b'e\x00s\x00p\x00a\x00\xf1\x00o\x00l\x00'在处理文件的上下文中最常见的是遇到 bytes 对象,其中可能不需要将所有数据隐式解码为 Unicode 字符串。
Booleans
Python 中的两个布尔值分别写为 True 和 False。比较和其他条件表达式的计算结果为 True 或 False。布尔值与 and 和 or 关键字组合:
In [95]: True and True
Out[95]: True
In [96]: False or True
Out[96]: True转换为数字时,False 变为 0,True 变为 1:
In [97]: int(False)
Out[97]: 0
In [98]: int(True)
Out[98]: 1该关键字 not 会将布尔值从 True 翻转为 False,反之亦然:
In [99]: a = True
In [100]: b = False
In [101]: not a
Out[101]: False
In [102]: not b
Out[102]: TrueType casting
str、bool、int 和 float 类型也是可用于将值转换为这些类型的函数:
In [103]: s = "3.14159"
In [104]: fval = float(s)
In [105]: type(fval)
Out[105]: float
In [106]: int(fval)
Out[106]: 3
In [107]: bool(fval)
Out[107]: True
In [108]: bool(0)
Out[108]: False请注意,大多数非零值在转换为 bool 时会变为 True。
None
None 是 Python 空值类型:
In [109]: a = None
In [110]: a is None
Out[110]: True
In [111]: b = 5
In [112]: b is not None
Out[112]: TrueNone 也是函数参数的常见默认值:
def add_and_maybe_multiply(a, b, c=None):
result = a + b
if c is not None:
result = result * c
return resultDates and times
内置的 Python datetime 模块提供了 datetime、date 和 time 类型。datetime 类型结合了 date 和 time 存储的信息,最常用:
In [113]: from datetime import datetime, date, time
In [114]: dt = datetime(2011, 10, 29, 20, 30, 21)
In [115]: dt.day
Out[115]: 29
In [116]: dt.minute
Out[116]: 30给定一个 datetime 实例,您可以通过调用 datetime 上同名的方法来提取等效的 date 和 time 对象:
In [117]: dt.date()
Out[117]: datetime.date(2011, 10, 29)
In [118]: dt.time()
Out[118]: datetime.time(20, 30, 21)strftime 方法将 datetime 格式化为字符串:
In [119]: dt.strftime("%Y-%m-%d %H:%M")
Out[119]: '2011-10-29 20:30'有关格式规范的完整列表,请参阅 Table 11.2。
当您聚合或以其他方式对时间序列数据进行分组时,替换一系列日期时间的 datetime 字段有时会很有用,例如,将 minute 和 second 字段替换为零:
In [121]: dt_hour = dt.replace(minute=0, second=0)
In [122]: dt_hour
Out[122]: datetime.datetime(2011, 10, 29, 20, 0)由于 datetime.datetime 是不可变类型,因此此类方法总是会生成新对象。所以在前面的例子中,dt 并没有被 replace 修改:
In [123]: dt
Out[123]: datetime.datetime(2011, 10, 29, 20, 30, 21)两个 datetime 对象的差异产生 datetime.timedelta 类型:
In [124]: dt2 = datetime(2011, 11, 15, 22, 30)
In [125]: delta = dt2 - dt
In [126]: delta
Out[126]: datetime.timedelta(days=17, seconds=7179)
In [127]: type(delta)
Out[127]: datetime.timedelta输出 timedelta(17, 7179) 表示 timedelta 编码了 17 天 7,179 秒的偏移量。
将 timedelta 添加到 datetime 会产生新的移位日期时间:
In [128]: dt
Out[128]: datetime.datetime(2011, 10, 29, 20, 30, 21)
In [129]: dt + delta
Out[129]: datetime.datetime(2011, 11, 15, 22, 30)2.3.3 Control Flow
Python 有几个内置关键字,用于条件逻辑、循环和其他编程语言中的其他标准控制流概念。
if, elif, and else
if 语句是最著名的控制流语句类型之一。它检查一个条件,如果为 True,则评估后面块中的代码:
x = -5
if x < 0:
print("It's negative")如果所有条件都为 False,则 if 语句后面可以选择跟随一个或多个 elif 块以及一个包罗万象的 else 块:
if x < 0:
print("It's negative")
elif x == 0:
print("Equal to zero")
elif 0 < x < 5:
print("Positive but smaller than 5")
else:
print("Positive and larger than or equal to 5")如果任何条件为 True,则不会再到达 elif 或 else 块。对于使用 and 或 or 的复合条件,条件从左到右计算并且会短路:
In [130]: a = 5; b = 7
In [131]: c = 8; d = 4
In [132]: if a < b or c > d:
.....: print("Made it")
Made it在此示例中,比较 c > d 永远不会被计算,因为第一个比较为 True。
也可以进行链式比较:
In [133]: 4 > 3 > 2 > 1
Out[133]: Truefor loops
for 循环用于迭代集合(如列表或元组)或迭代器。for 循环的标准语法是:
for value in collection:
# do something with value您可以使用 continue 关键字将 for 循环推进到下一次迭代,跳过块的其余部分。考虑以下代码,它将列表中的整数相加并跳过 None 值:
sequence = [1, 2, None, 4, None, 5]
total = 0
for value in sequence:
if value is None:
continue
total += value可以使用 break 关键字一起退出 for 循环。此代码对列表中的元素求和,直到达到 5:
sequence = [1, 2, 0, 4, 6, 5, 2, 1]
total_until_5 = 0
for value in sequence:
if value == 5:
break
total_until_5 += valuebreak 关键字仅终止最内层的 for 循环;任何外部 for 循环将继续运行:
In [134]: for i in range(4):
.....: for j in range(4):
.....: if j > i:
.....: break
.....: print((i, j))
.....:
(0, 0)
(1, 0)
(1, 1)
(2, 0)
(2, 1)
(2, 2)
(3, 0)
(3, 1)
(3, 2)
(3, 3)正如我们将更详细地看到的,如果集合或迭代器中的元素是序列(例如元组或列表),则可以方便地将它们解包到 for 循环语句中的变量中:
for a, b, c in iterator:
# do somethingwhile loops
while 循环指定一个条件和一个要执行的代码块,直到条件计算结果为 False 或循环以 break 显式结束:
x = 256
total = 0
while x > 0:
if total > 500:
break
total += x
x = x // 2pass
pass 是 Python 中的“no-op”(或“不执行任何操作”)语句。它可以用在不采取任何操作的块中(或者作为尚未实现的代码的占位符);它是必需的,只是因为 Python 使用空格来分隔块:
if x < 0:
print("negative!")
elif x == 0:
# TODO: put something smart here
pass
else:
print("positive!")range
range 函数生成均匀间隔的整数序列:
In [135]: range(10)
Out[135]: range(0, 10)
In [136]: list(range(10))
Out[136]: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]可以给出开始、结束和步骤(可能是负数):
In [137]: list(range(0, 20, 2))
Out[137]: [0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
In [138]: list(range(5, 0, -1))
Out[138]: [5, 4, 3, 2, 1]正如您所看到的,range 生成直到但不包括端点的整数。range 的常见用途是按索引迭代序列:
In [139]: seq = [1, 2, 3, 4]
In [140]: for i in range(len(seq)):
.....: print(f"element {i}: {seq[i]}")
element 0: 1
element 1: 2
element 2: 3
element 3: 4虽然您可以使用 list 等函数将 range 生成的所有整数存储在其他数据结构中,但通常默认的迭代器形式就是您想要的。此代码片段将 0 到 99,999 之间所有 3 或 5 的倍数的数字相加:
In [141]: total = 0
In [142]: for i in range(100_000):
.....: # % is the modulo operator
.....: if i % 3 == 0 or i % 5 == 0:
.....: total += i
In [143]: print(total)
2333316668虽然生成的范围可以任意大,但任何给定时间的内存使用量可能非常小。
2.4 Conclusion
本章简要介绍了一些基本的 Python 语言概念以及 IPython 和 Jupyter 编程环境。在下一章中,我将讨论许多内置数据类型、函数和输入输出实用程序,这些内容将在本书的其余部分中不断使用。