4 NumPy Basics: Arrays and Vectorized Computation
NumPy 是 Numerical Python 的缩写,是 Python 数值计算最重要的基础包之一。许多提供科学功能的计算包使用 NumPy 的数组对象作为数据交换的标准接口语言之一。我介绍的许多有关 NumPy 的知识也可以转移到 pandas 上。
以下是您将在 NumPy 中找到的一些内容:
ndarray,一种高效的多维数组,提供快速的面向数组的算术运算和灵活的广播功能
用于对整个数据数组进行快速运算的数学函数,而无需编写循环
用于将数组数据读取/写入磁盘以及使用内存映射文件的工具
线性代数、随机数生成和傅里叶变换功能
用于将 NumPy 与用 C、C++ 或 FORTRAN 编写的库连接的 C API
由于 NumPy 提供了全面且文档齐全的 C API,因此可以轻松地将数据传递到用低级语言编写的外部库,并且外部库可以将数据作为 NumPy 数组返回到 Python。此功能使 Python 成为包装旧版 C、C++ 或 FORTRAN 代码库并为它们提供动态且可访问的界面的首选语言。
虽然 NumPy 本身不提供建模或科学功能,但了解 NumPy 数组和面向数组的计算将帮助您更有效地使用具有数组计算语义的工具,例如 pandas。由于 NumPy 是一个很大的主题,我将在稍后更深入地介绍许多高级 NumPy 功能,例如广播(请参阅 Appendix A: Advanced NumPy)。本书的其余部分不需要这些高级功能,但是当您更深入地使用 Python 进行科学计算时,它们可能会对您有所帮助。
对于大多数数据分析应用程序,我将重点关注的主要功能领域是:
快速基于数组的操作,用于数据修改和清理、子集化和过滤、转换以及任何其他类型的计算
常见的数组算法,例如排序、唯一和集合运算
高效的描述性统计和汇总/总结数据
用于合并和连接异构数据集的数据对齐和关系数据操作
将条件逻辑表示为数组表达式,而不是使用
if-elif-else分支的循环分组数据操作(聚合、转换和函数应用)
虽然 NumPy 为一般数值数据处理提供了计算基础,但许多读者希望使用 pandas 作为大多数类型的统计或分析的基础,尤其是表格数据。此外,pandas 还提供了一些更多特定领域的功能,例如时间序列操作,这是 NumPy 中不存在的。
Python 中面向数组的计算的根源可以追溯到 1995 年,当时 Jim Hugunin 创建了 Numeric 库。在接下来的 10 年里,许多科学编程社区开始使用 Python 进行数组编程,但图书馆生态系统在 2000 年代初期已经变得支离破碎。2005 年,Travis Oliphant 将当时的 Numeric 和 Numarray 项目打造为 NumPy 项目,将社区聚集在一个数组计算框架周围。
NumPy 对于 Python 中的数值计算如此重要的原因之一是它是为提高大型数据数组的效率而设计的。造成这种情况的原因有很多:
NumPy 在内部将数据存储在连续的内存块中,独立于其他内置 Python 对象。 NumPy 的用 C 语言编写的算法库可以在此内存上运行,无需任何类型检查或其他开销。NumPy 数组使用的内存也比内置 Python 序列少得多。
NumPy 操作可以对整个数组执行复杂的计算,而无需使用 Python
for循环(这对于大型序列来说可能会很慢)。NumPy 比常规 Python 代码更快,因为其基于 C 的算法避免了常规解释的 Python 代码带来的开销。
为了让您了解性能差异,请考虑一个包含一百万个整数的 NumPy 数组以及等效的 Python 列表:
In [7]: import numpy as np
In [8]: my_arr = np.arange(1_000_000)
In [9]: my_list = list(range(1_000_000))现在让我们将每个序列乘以 2:
In [10]: %timeit my_arr2 = my_arr * 2
309 us +- 7.48 us per loop (mean +- std. dev. of 7 runs, 1000 loops each)
In [11]: %timeit my_list2 = [x * 2 for x in my_list]
46.4 ms +- 526 us per loop (mean +- std. dev. of 7 runs, 10 loops each)基于 NumPy 的算法通常比纯 Python 算法快 10 到 100 倍(或更多),并且使用的内存显着减少。
4.1 The NumPy ndarray: A Multidimensional Array Object
NumPy 的主要功能之一是它的 N 维数组对象(或 ndarray),它是 Python 中大型数据集的快速、灵活的容器。数组使您能够使用与标量元素之间的等效运算类似的语法对整个数据块执行数学运算。
为了让您了解 NumPy 如何使用与内置 Python 对象上的标量值类似的语法启用批量计算,我首先导入 NumPy 并创建一个小数组:
In [12]: import numpy as np
In [13]: data = np.array([[1.5, -0.1, 3], [0, -3, 6.5]])
In [14]: data
Out[14]:
array([[ 1.5, -0.1, 3. ],
[ 0. , -3. , 6.5]])然后我用 data 编写数学运算:
In [15]: data * 10
Out[15]:
array([[ 15., -1., 30.],
[ 0., -30., 65.]])
In [16]: data + data
Out[16]:
array([[ 3. , -0.2, 6. ],
[ 0. , -6. , 13. ]])在第一个示例中,所有元素都已乘以 10。在第二个示例中,数组中每个“单元格”中的对应值已相互相加。
在本章和整本书中,我使用标准 NumPy 约定,即始终使用 import numpy as np。可以在代码中放入 from numpy import * 以避免编写 np.,但我建议不要养成这种习惯。numpy 命名空间很大,包含许多名称与内置 Python 函数(例如 min 和 max)冲突的函数。遵循这些标准约定几乎总是一个好主意。
ndarray 是同质数据的通用多维容器;也就是说,所有元素必须是同一类型。每个数组都有一个 shape(表示每个维度大小的元组)和一个 dtype(描述数组数据类型的对象):
In [17]: data.shape
Out[17]: (2, 3)
In [18]: data.dtype
Out[18]: dtype('float64')本章将向您介绍使用 NumPy 数组的基础知识,这对于阅读本书的其余部分应该足够了。虽然对于许多数据分析应用程序来说,不需要深入了解 NumPy,但精通面向数组的编程和思维是成为科学 Python 大师的关键一步。
每当您在书中看到 “array”、“NumPy array” 或 “ndarray” 时,大多数情况下它们都指的是 ndarray 对象。
4.1.1 Creating ndarrays
创建数组最简单的方法是使用 array 函数。这接受任何类似序列的对象(包括其他数组)并生成一个包含传递数据的新 NumPy 数组。例如,列表是一个很好的转换候选:
In [19]: data1 = [6, 7.5, 8, 0, 1]
In [20]: arr1 = np.array(data1)
In [21]: arr1
Out[21]: array([6. , 7.5, 8. , 0. , 1. ])嵌套序列,就像等长列表的列表一样,将被转换为多维数组:
In [22]: data2 = [[1, 2, 3, 4], [5, 6, 7, 8]]
In [23]: arr2 = np.array(data2)
In [24]: arr2
Out[24]:
array([[1, 2, 3, 4],
[5, 6, 7, 8]])由于 data2 是列表的列表,因此 NumPy 数组 arr2 具有两个维度,其形状从数据推断。我们可以通过检查 ndim 和 shape 属性来确认这一点:
In [25]: arr2.ndim
Out[25]: 2
In [26]: arr2.shape
Out[26]: (2, 4)除非明确指定(在 Data Types for ndarrays 中讨论),否则 numpy.array 会尝试为其创建的数组推断良好的数据类型。数据类型存储在特殊的 dtype metadata 对象中;例如,在前面的两个例子中,我们有:
In [27]: arr1.dtype
Out[27]: dtype('float64')
In [28]: arr2.dtype
Out[28]: dtype('int64')除了 numpy.array 之外,还有许多其他函数用于创建新数组。例如,numpy.zeros 和 numpy.ones 分别创建具有给定长度或形状的 0 或 1 数组。numpy.empty 创建一个数组,而不将其值初始化为任何特定值。要使用这些方法创建高维数组,请传递形状的元组:
In [29]: np.zeros(10)
Out[29]: array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
In [30]: np.zeros((3, 6))
Out[30]:
array([[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]])
In [31]: np.empty((2, 3, 2))
Out[31]:
array([[[0., 0.],
[0., 0.],
[0., 0.]],
[[0., 0.],
[0., 0.],
[0., 0.]]])假设 numpy.empty 将返回全零的数组是不安全的。该函数返回未初始化的内存,因此可能包含非零“垃圾”值。仅当您打算用数据填充新数组时才应使用此函数。
numpy.arange 是内置 Python range 函数的数组值版本:
In [32]: np.arange(15)
Out[32]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])有关标准数组创建函数的简短列表,请参阅 Table 4.1。由于 NumPy 专注于数值计算,因此如果未指定数据类型,在许多情况下将是 float64(浮点)。
| Function | Description |
|---|---|
array |
通过推断数据类型或显式指定数据类型,将输入数据(列表、元组、数组或其他序列类型)转换为 ndarray;默认复制输入数据 |
asarray |
将输入转换为 ndarray,但如果输入已经是 ndarray,则不复制 |
arange |
与内置 range 类似,但返回 ndarray 而不是列表 |
ones, ones_like |
生成具有给定形状和数据类型的全 1 数组;ones_Like 采用另一个数组并生成具有相同形状和数据类型的 ones 数组 |
zeros, zeros_like |
与 ones 和 ones_like 类似,但生成 0 数组 |
empty, empty_like |
通过分配新内存来创建新数组,但不填充任何值 |
full, full_like |
生成给定形状和数据类型的数组,并将所有值设置为指示的“填充值”;full_like 接受另一个数组并生成具有相同形状和数据类型的填充数组 |
eye, identity |
创建一个 N × N 方阵单位矩阵(对角线上为 1,其他位置为 0) |
4.1.2 Data Types for ndarrays
数据类型或 dtype 是一个特殊对象,包含 ndarray 将一块内存解释为特定类型数据所需的信息(或元数据、有关数据的数据):
In [33]: arr1 = np.array([1, 2, 3], dtype=np.float64)
In [34]: arr2 = np.array([1, 2, 3], dtype=np.int32)
In [35]: arr1.dtype
Out[35]: dtype('float64')
In [36]: arr2.dtype
Out[36]: dtype('int32')数据类型是 NumPy 与来自其他系统的数据交互的灵活性的来源。在大多数情况下,它们直接提供到底层磁盘或内存表示的映射,这使得可以在磁盘上读取和写入二进制数据流,并连接到用 C 或 FORTRAN 等低级语言编写的代码。数字数据类型的命名方式相同:类型名称,如 float 或 int,后跟一个数字,表示每个元素的位数。标准双精度浮点值(Python 的 float 对象中使用的值)占用 8 个字节或 64 位。因此,这种类型在 NumPy 中称为 float64。有关 NumPy 支持的数据类型的完整列表,请参阅 Table 4.2。
不用担心记住 NumPy 数据类型,特别是如果您是新用户。通常只需要关心正在处理的一般数据类型,无论是浮点、复数、整数、布尔值、字符串还是一般的 Python 对象。当您需要更多地控制数据在内存和磁盘上的存储方式(尤其是大型数据集)时,最好知道您可以控制存储类型。
| Type | Type code | Description |
|---|---|---|
int8, uint8 |
i1, u1 |
Signed and unsigned 8-bit (1 byte) integer types |
int16, uint16 |
i2, u2 |
Signed and unsigned 16-bit integer types |
int32, uint32 |
i4, u4 |
Signed and unsigned 32-bit integer types |
int64, uint64 |
i8, u8 |
Signed and unsigned 64-bit integer types |
float16 |
f2 |
Half-precision floating point |
float32 |
f4 or f |
Standard single-precision floating point; compatible with C float |
float64 |
f8 or d |
Standard double-precision floating point; compatible with C double and Python float object |
float128 |
f16 or g |
Extended-precision floating point |
complex64, complex128, complex256 |
c8, c16, c32 |
Complex numbers represented by two 32, 64, or 128 floats, respectively |
bool |
? |
Boolean type storing True and False values |
object |
O |
Python object type; a value can be any Python object |
string_ |
S |
Fixed-length ASCII string type (1 byte per character); for example, to create a string data type with length 10, use 'S10' |
unicode_ |
U | Fixed-length Unicode type (number of bytes platform specific); same specification semantics as string_ (e.g., 'U10') |
整数类型有有符号和无符号之分,许多读者对这个术语并不熟悉。有符号整数可以表示正整数和负整数,而无符号整数只能表示非零整数。例如,int8(有符号 8-bit 整数)可以表示从 -128 到 127(含)的整数,而 uint8(无符号 8-bit 整数)可以表示 0 到 255。
您可以使用 ndarray 的 astype 方法将数组从一种数据类型显式转换或转换为另一种数据类型:
In [37]: arr = np.array([1, 2, 3, 4, 5])
In [38]: arr.dtype
Out[38]: dtype('int64')
In [39]: float_arr = arr.astype(np.float64)
In [40]: float_arr
Out[40]: array([1., 2., 3., 4., 5.])
In [41]: float_arr.dtype
Out[41]: dtype('float64')在此示例中,整数被转换为浮点数。如果我将一些浮点数转换为整数数据类型,小数部分将被截断:
In [42]: arr = np.array([3.7, -1.2, -2.6, 0.5, 12.9, 10.1])
In [43]: arr
Out[43]: array([ 3.7, -1.2, -2.6, 0.5, 12.9, 10.1])
In [44]: arr.astype(np.int32)
Out[44]: array([ 3, -1, -2, 0, 12, 10], dtype=int32)如果您有一个表示数字的字符串数组,则可以使用 astype 将它们转换为数字形式:
In [45]: numeric_strings = np.array(["1.25", "-9.6", "42"], dtype=np.string_)
In [46]: numeric_strings.astype(float)
Out[46]: array([ 1.25, -9.6 , 42. ])使用 numpy.string_ 类型时要小心,因为 NumPy 中的字符串数据是固定大小的,可能会在没有警告的情况下截断输入。pandas 对非数字数据有更直观的开箱即用行为。
如果由于某种原因转换失败(例如无法转换为 float64 的字符串),则会引发 ValueError。之前我有点懒,写了 float 而不是 np.float64;NumPy 将 Python 类型别名为其自己的等效数据类型。
您还可以使用另一个数组的 dtype 属性:
In [47]: int_array = np.arange(10)
In [48]: calibers = np.array([.22, .270, .357, .380, .44, .50], dtype=np.float64)
In [49]: int_array.astype(calibers.dtype)
Out[49]: array([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])您还可以使用速记类型代码字符串来引用 dtype:
In [50]: zeros_uint32 = np.zeros(8, dtype="u4")
In [51]: zeros_uint32
Out[51]: array([0, 0, 0, 0, 0, 0, 0, 0], dtype=uint32)调用 astype 始终会创建一个新数组(数据的副本),即使新数据类型与旧数据类型相同。
4.1.3 Arithmetic with NumPy Arrays
数组很重要,因为它们使您能够表达对数据的批量操作,而无需编写任何 for 循环。NumPy 用户将此称为矢量化(vectorization)。大小相等的数组之间的任何算术运算都按元素应用运算:
In [52]: arr = np.array([[1., 2., 3.], [4., 5., 6.]])
In [53]: arr
Out[53]:
array([[1., 2., 3.],
[4., 5., 6.]])
In [54]: arr * arr
Out[54]:
array([[ 1., 4., 9.],
[16., 25., 36.]])
In [55]: arr - arr
Out[55]:
array([[0., 0., 0.],
[0., 0., 0.]])标量算术运算将标量参数传播到数组中的每个元素:
In [56]: 1 / arr
Out[56]:
array([[1. , 0.5 , 0.3333],
[0.25 , 0.2 , 0.1667]])
In [57]: arr ** 2
Out[57]:
array([[ 1., 4., 9.],
[16., 25., 36.]])相同大小的数组之间的比较会产生布尔数组:
In [58]: arr2 = np.array([[0., 4., 1.], [7., 2., 12.]])
In [59]: arr2
Out[59]:
array([[ 0., 4., 1.],
[ 7., 2., 12.]])
In [60]: arr2 > arr
Out[60]:
array([[False, True, False],
[ True, False, True]])评估不同大小的数组之间的操作称为广播(broadcasting),将在 Appendix A: Advanced NumPy 中更详细地讨论。对于本书的大部分内容来说,并不需要对广播有深入的了解。
4.1.4 Basic Indexing and Slicing
NumPy 数组索引是一个深入的主题,因为您可能希望通过多种方式选择数据子集或单个元素。一维数组很简单;从表面上看,它们的行为与 Python 列表类似:
In [61]: arr = np.arange(10)
In [62]: arr
Out[62]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [63]: arr[5]
Out[63]: 5
In [64]: arr[5:8]
Out[64]: array([5, 6, 7])
In [65]: arr[5:8] = 12
In [66]: arr
Out[66]: array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9])正如您所看到的,如果您将标量值分配给切片,如 arr[5:8] = 12 所示,该值将传播(或广播)到整个选择。
与 Python 内置列表的第一个重要区别是数组切片是原始数组的视图。这意味着数据不会被复制,对视图的任何修改都将反映在源数组中。
举个例子,我首先创建 arr 的切片:
In [67]: arr_slice = arr[5:8]
In [68]: arr_slice
Out[68]: array([12, 12, 12])现在,当我更改 arr_slice 中的值时,突变会反映在原始数组 arr 中:
In [69]: arr_slice[1] = 12345
In [70]: arr
Out[70]:
array([ 0, 1, 2, 3, 4, 12, 12345, 12, 8,
9])“裸”切片 [:] 将分配给数组中的所有值:
In [71]: arr_slice[:] = 64
In [72]: arr
Out[72]: array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])如果您是 NumPy 的新手,您可能会对此感到惊讶,特别是如果您使用过其他更热衷于复制数据的数组编程语言。由于 NumPy 被设计为能够处理非常大的数组,因此如果 NumPy 坚持始终复制数据,您可以想象性能和内存问题。
如果您想要 ndarray 切片的副本而不是视图,则需要显式复制该数组,例如 arr[5:8].copy()。正如您将看到的,pandas 也是这样工作的。
对于更高维的数组,您有更多的选择。在二维数组中,每个索引处的元素不再是标量,而是一维数组:
In [73]: arr2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
In [74]: arr2d[2]
Out[74]: array([7, 8, 9])因此,可以递归地访问各个元素。但这有点太多的工作,因此您可以传递一个以逗号分隔的索引列表来选择单个元素。所以这些是等价的:
In [75]: arr2d[0][2]
Out[75]: 3
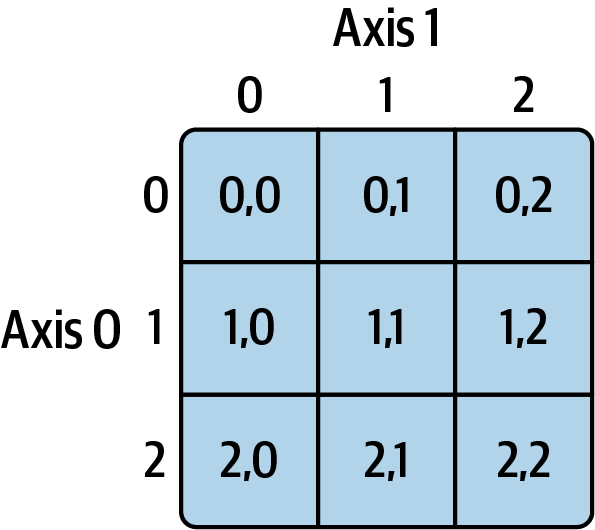
In [76]: arr2d[0, 2]
Out[76]: 3有关二维数组索引的说明,请参见 Figure 4.1。我发现将 axis 0 视为数组的 “rows”,将 axis 1 视为 “columns” 很有帮助。
在多维数组中,如果省略后面的索引,则返回的对象将是一个较低维度的 ndarray,由较高维度上的所有数据组成。所以在 2 × 2 × 3 数组 arr3d 中:
In [77]: arr3d = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
In [78]: arr3d
Out[78]:
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])arr3d[0] 是一个 2 × 3 数组:
In [79]: arr3d[0]
Out[79]:
array([[1, 2, 3],
[4, 5, 6]])标量值和数组都可以分配给 arr3d[0]:
In [80]: old_values = arr3d[0].copy()
In [81]: arr3d[0] = 42
In [82]: arr3d
Out[82]:
array([[[42, 42, 42],
[42, 42, 42]],
[[ 7, 8, 9],
[10, 11, 12]]])
In [83]: arr3d[0] = old_values
In [84]: arr3d
Out[84]:
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[ 7, 8, 9],
[10, 11, 12]]])类似地,arr3d[1, 0] 给出索引以 (1, 0) 开头的所有值,形成一维数组:
In [85]: arr3d[1, 0]
Out[85]: array([7, 8, 9])这个表达式与我们分两步索引的表达式相同:
In [86]: x = arr3d[1]
In [87]: x
Out[87]:
array([[ 7, 8, 9],
[10, 11, 12]])
In [88]: x[0]
Out[88]: array([7, 8, 9])请注意,在所有选择数组子部分的情况下,返回的数组都是视图。
NumPy 数组的这种多维索引语法不适用于常规 Python 对象,例如列表列表。
Indexing with slices
与 Python 列表等一维对象一样,ndarray 可以使用熟悉的语法进行切片:
In [89]: arr
Out[89]: array([ 0, 1, 2, 3, 4, 64, 64, 64, 8, 9])
In [90]: arr[1:6]
Out[90]: array([ 1, 2, 3, 4, 64])考虑之前的二维数组 arr2d。对该数组进行切片有点不同:
In [91]: arr2d
Out[91]:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
In [92]: arr2d[:2]
Out[92]:
array([[1, 2, 3],
[4, 5, 6]])如您所见,它已沿 axis 0(第一个轴)进行切片。因此,切片沿着轴选择一系列元素。将表达式 arr2d[:2] 理解为“选择 arr2d 的前两行”会很有帮助。
您可以传递多个切片,就像传递多个索引一样:
In [93]: arr2d[:2, 1:]
Out[93]:
array([[2, 3],
[5, 6]])当像这样切片时,您总是获得相同维数的数组视图。通过混合整数索引和切片,您可以获得较低维度的切片。
例如,我可以选择第二行,但只能选择前两列,如下所示:
In [94]: lower_dim_slice = arr2d[1, :2]这里,arr2d 是二维的,而 lower_dim_slice 是一维的,它的形状是一个只有一个 axis 大小的元组:
In [95]: lower_dim_slice.shape
Out[95]: (2,)同样,我可以选择第三列,但只能选择前两行,如下所示:
In [96]: arr2d[:2, 2]
Out[96]: array([3, 6])有关说明,请参见 Figure 4.2。请注意,冒号本身意味着获取整个轴,因此您可以通过执行以下操作仅切片更高维度的轴:
In [97]: arr2d[:, :1]
Out[97]:
array([[1],
[4],
[7]])当然,分配给切片表达式会分配给整个选择:
In [98]: arr2d[:2, 1:] = 0
In [99]: arr2d
Out[99]:
array([[1, 0, 0],
[4, 0, 0],
[7, 8, 9]])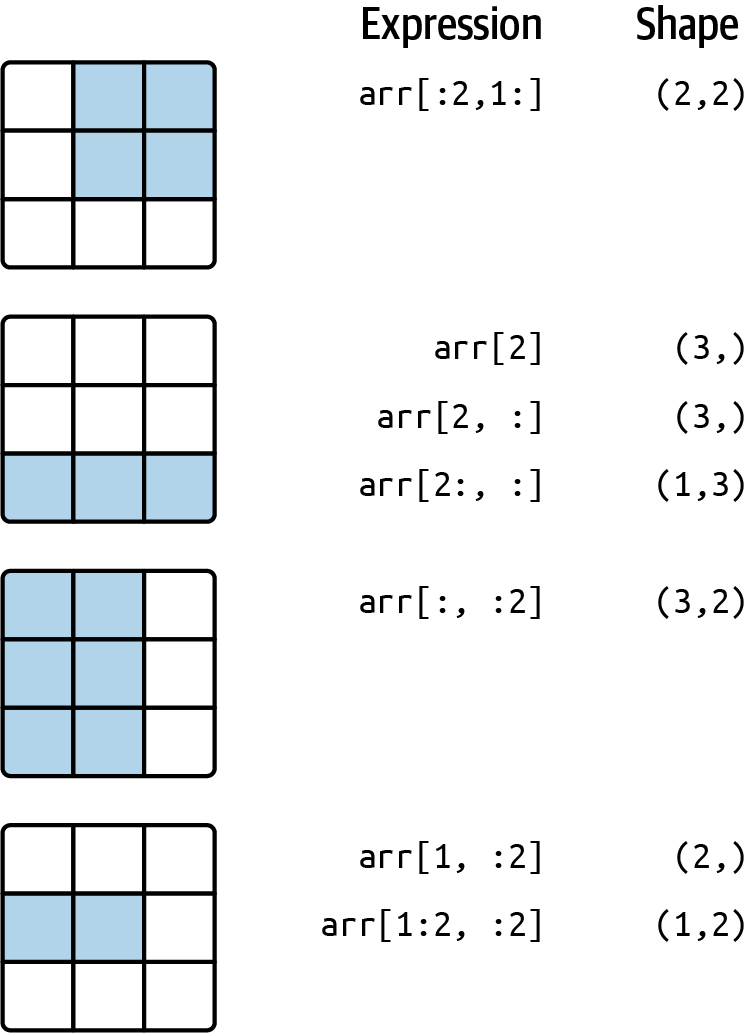
4.1.5 Boolean Indexing
让我们考虑一个示例,其中数组中有一些数据,并且名称数组中有重复项:
In [100]: names = np.array(["Bob", "Joe", "Will", "Bob", "Will", "Joe", "Joe"])
In [101]: data = np.array([[4, 7], [0, 2], [-5, 6], [0, 0], [1, 2],
.....: [-12, -4], [3, 4]])
In [102]: names
Out[102]: array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe'], dtype='<U4')
In [103]: data
Out[103]:
array([[ 4, 7],
[ 0, 2],
[ -5, 6],
[ 0, 0],
[ 1, 2],
[-12, -4],
[ 3, 4]])假设每个名称对应于 data 数组中的一行,并且我们想要选择具有相应名称"Bob"的所有行。与算术运算一样,与数组的比较(例如 ==)也被向量化。因此,将name与字符串"Bob"进行比较会产生一个布尔数组:
In [104]: names == "Bob"
Out[104]: array([ True, False, False, True, False, False, False])索引数组时可以传递这个布尔数组:
In [105]: data[names == "Bob"]
Out[105]:
array([[4, 7],
[0, 0]])布尔数组的长度必须与其索引的数组轴的长度相同。您甚至可以将布尔数组与切片或整数(或整数序列;稍后详细介绍)混合搭配。
在这些示例中,我从names=="Bob"的行中进行选择,并对列进行索引:
In [106]: data[names == "Bob", 1:]
Out[106]:
array([[7],
[0]])
In [107]: data[names == "Bob", 1]
Out[107]: array([7, 0])要选择除"Bob"之外的所有内容,您可以使用 != 或使用 ~ 否定条件:
In [108]: names != "Bob"
Out[108]: array([False, True, True, False, True, True, True])
In [109]: ~(names == "Bob")
Out[109]: array([False, True, True, False, True, True, True])
In [110]: data[~(names == "Bob")]
Out[110]:
array([[ 0, 2],
[ -5, 6],
[ 1, 2],
[-12, -4],
[ 3, 4]])当您想要反转变量引用的布尔数组时,~ 运算符会很有用:
In [111]: cond = names == "Bob"
In [112]: data[~cond]
Out[112]:
array([[ 0, 2],
[ -5, 6],
[ 1, 2],
[-12, -4],
[ 3, 4]])要选择三个名称中的两个来组合多个布尔条件,请使用布尔算术运算符,例如 &(and)和 |(or):
In [113]: mask = (names == "Bob") | (names == "Will")
In [114]: mask
Out[114]: array([ True, False, True, True, True, False, False])
In [115]: data[mask]
Out[115]:
array([[ 4, 7],
[-5, 6],
[ 0, 0],
[ 1, 2]])通过布尔索引从数组中选择数据并将结果分配给新变量始终会创建数据的副本,即使返回的数组未更改也是如此。
Python 关键字 and 和 or 不适用于布尔数组。使用 &(and)和 | (or)代替。
使用布尔数组设置值的方法是将右侧的一个或多个值替换到布尔数组值为 True 的位置。要将 data 中的所有负值设置为 0,我们只需要做:
In [116]: data[data < 0] = 0
In [117]: data
Out[117]:
array([[4, 7],
[0, 2],
[0, 6],
[0, 0],
[1, 2],
[0, 0],
[3, 4]])您还可以使用一维布尔数组设置整行或整列:
In [118]: data[names != "Joe"] = 7
In [119]: data
Out[119]:
array([[7, 7],
[0, 2],
[7, 7],
[7, 7],
[7, 7],
[0, 0],
[3, 4]])正如我们稍后将看到的,使用 pandas 可以方便地对二维数据进行这些类型的操作。
4.1.6 Fancy Indexing
花式索引是 NumPy 采用的一个术语,用于描述使用整数数组进行索引。假设我们有一个 8 × 4 数组:
In [120]: arr = np.zeros((8, 4))
In [121]: for i in range(8):
.....: arr[i] = i
In [122]: arr
Out[122]:
array([[0., 0., 0., 0.],
[1., 1., 1., 1.],
[2., 2., 2., 2.],
[3., 3., 3., 3.],
[4., 4., 4., 4.],
[5., 5., 5., 5.],
[6., 6., 6., 6.],
[7., 7., 7., 7.]])要按特定顺序选择行的子集,您可以简单地传递指定所需顺序的整数列表或 ndarray:
In [123]: arr[[4, 3, 0, 6]]
Out[123]:
array([[4., 4., 4., 4.],
[3., 3., 3., 3.],
[0., 0., 0., 0.],
[6., 6., 6., 6.]])希望这段代码达到了您的预期!使用负索引从末尾选择行:
In [124]: arr[[-3, -5, -7]]
Out[124]:
array([[5., 5., 5., 5.],
[3., 3., 3., 3.],
[1., 1., 1., 1.]])传递多个索引数组的作用略有不同;它选择与每个索引元组相对应的一维元素数组:
In [125]: arr = np.arange(32).reshape((8, 4))
In [126]: arr
Out[126]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]])
In [127]: arr[[1, 5, 7, 2], [0, 3, 1, 2]]
Out[127]: array([ 4, 23, 29, 10])要了解有关 reshape 方法的更多信息,请查看 Appendix A: Advanced NumPy。
这里选择元素 (1, 0)、(5, 3)、(7, 1)、(2, 2)。使用与轴数量一样多的整数数组进行花式索引的结果始终是一维的。
在这种情况下,花式索引的行为与某些用户(包括我自己)的预期有点不同,即通过选择矩阵的行和列的子集形成的矩形区域。这是实现这一点的一种方法:
In [128]: arr[[1, 5, 7, 2]][:, [0, 3, 1, 2]]
Out[128]:
array([[ 4, 7, 5, 6],
[20, 23, 21, 22],
[28, 31, 29, 30],
[ 8, 11, 9, 10]])请记住,与切片不同,花式索引在将结果分配给新变量时始终将数据复制到新数组中。如果您使用花哨的索引分配值,则索引值将被修改:
In [129]: arr[[1, 5, 7, 2], [0, 3, 1, 2]]
Out[129]: array([ 4, 23, 29, 10])
In [130]: arr[[1, 5, 7, 2], [0, 3, 1, 2]] = 0
In [131]: arr
Out[131]:
array([[ 0, 1, 2, 3],
[ 0, 5, 6, 7],
[ 8, 9, 0, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 0],
[24, 25, 26, 27],
[28, 0, 30, 31]])4.1.7 Transposing Arrays and Swapping Axes
转置是一种特殊的重塑形式,它同样会返回基础数据的视图,而无需复制任何内容。数组具有 transpose 方法和特殊的 T 属性:
In [132]: arr = np.arange(15).reshape((3, 5))
In [133]: arr
Out[133]:
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
In [134]: arr.T
Out[134]:
array([[ 0, 5, 10],
[ 1, 6, 11],
[ 2, 7, 12],
[ 3, 8, 13],
[ 4, 9, 14]])在进行矩阵计算时,您可能会经常这样做 - 例如,在使用 numpy.dot 计算内部矩阵乘积时:
In [135]: arr = np.array([[0, 1, 0], [1, 2, -2], [6, 3, 2], [-1, 0, -1], [1, 0, 1
]])
In [136]: arr
Out[136]:
array([[ 0, 1, 0],
[ 1, 2, -2],
[ 6, 3, 2],
[-1, 0, -1],
[ 1, 0, 1]])
In [137]: np.dot(arr.T, arr)
Out[137]:
array([[39, 20, 12],
[20, 14, 2],
[12, 2, 10]])@ 中缀运算符是进行矩阵乘法的另一种方法:
In [138]: arr.T @ arr
Out[138]:
array([[39, 20, 12],
[20, 14, 2],
[12, 2, 10]])使用 .T 进行简单转置是交换轴的特殊情况。ndarray 具有 swapaxes 方法,该方法采用一对轴编号并切换指示的轴以重新排列数据:
In [139]: arr
Out[139]:
array([[ 0, 1, 0],
[ 1, 2, -2],
[ 6, 3, 2],
[-1, 0, -1],
[ 1, 0, 1]])
In [140]: arr.swapaxes(0, 1)
Out[140]:
array([[ 0, 1, 6, -1, 1],
[ 1, 2, 3, 0, 0],
[ 0, -2, 2, -1, 1]])swapaxes 类似地返回数据视图而不制作副本。
4.2 Pseudorandom Number Generation
numpy.random 模块补充了内置 Python random 模块的功能,可从多种概率分布中高效生成样本值的整个数组。例如,您可以使用 numpy.random.standard_normal 从标准正态分布中获取 4 × 4 样本数组:
In [141]: samples = np.random.standard_normal(size=(4, 4))
In [142]: samples
Out[142]:
array([[-0.2047, 0.4789, -0.5194, -0.5557],
[ 1.9658, 1.3934, 0.0929, 0.2817],
[ 0.769 , 1.2464, 1.0072, -1.2962],
[ 0.275 , 0.2289, 1.3529, 0.8864]])相比之下,Python 的内置 random 模块一次仅采样一个值。从这个基准测试中可以看出,numpy.random 生成非常大的样本的速度要快一个数量级:
In [143]: from random import normalvariate
In [144]: N = 1_000_000
In [145]: %timeit samples = [normalvariate(0, 1) for _ in range(N)]
490 ms +- 2.23 ms per loop (mean +- std. dev. of 7 runs, 1 loop each)
In [146]: %timeit np.random.standard_normal(N)
32.6 ms +- 271 us per loop (mean +- std. dev. of 7 runs, 10 loops each)这些随机数不是真正随机的(而是伪随机的),而是由可配置的随机数生成器生成,该生成器确定性地确定创建什么值。像 numpy.random.standard_normal 这样的函数使用 numpy.random 模块的默认随机数生成器,但您的代码可以配置为使用显式生成器:
In [147]: rng = np.random.default_rng(seed=12345)
In [148]: data = rng.standard_normal((2, 3))seed 参数决定了生成器的初始状态,每次使用 rng 对象生成数据时状态都会发生变化。生成器对象 rng 也与可能使用 numpy.random 模块的其他代码隔离:
In [149]: type(rng)
Out[149]: numpy.random._generator.Generator请参阅 Table 4.3,了解随机生成器对象(如 rng)上可用的方法的部分列表。在本章的其余部分中,我将使用上面创建的 rng 对象来生成随机数据。
| Method | Description |
|---|---|
permutation |
返回序列的随机排列,或返回排列范围 |
shuffle |
就地随机排列序列 |
uniform |
从均匀分布中抽取样本 |
integers |
从给定的低到高范围内抽取随机整数 |
standard_normal |
从平均值为 0、标准差为 1 的正态分布中抽取样本 |
binomial |
从二项式分布中抽取样本 |
normal |
从正态(高斯)分布中抽取样本 |
beta |
从 beta 分布中抽取样本 |
chisquare |
从卡方分布中抽取样本 |
gamma |
从伽玛分布中提取样本 |
uniform |
从均匀 [0, 1) 分布中抽取样本 |
4.3 Universal Functions: Fast Element-Wise Array Functions
通用函数(或 ufunc)是对 ndarray 中的数据执行逐元素操作的函数。您可以将它们视为简单函数的快速矢量化包装器,这些函数采用一个或多个标量值并生成一个或多个标量结果。
许多 ufunc 都是简单的逐元素转换,例如 numpy.sqrt 或 numpy.exp:
In [150]: arr = np.arange(10)
In [151]: arr
Out[151]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [152]: np.sqrt(arr)
Out[152]:
array([0. , 1. , 1.4142, 1.7321, 2. , 2.2361, 2.4495, 2.6458,
2.8284, 3. ])
In [153]: np.exp(arr)
Out[153]:
array([ 1. , 2.7183, 7.3891, 20.0855, 54.5982, 148.4132,
403.4288, 1096.6332, 2980.958 , 8103.0839])这些被称为一元 ufunc。其他的,例如 numpy.add 或 numpy.maximum,采用两个数组(因此,二进制 ufunc)并返回一个数组作为结果:
In [154]: x = rng.standard_normal(8)
In [155]: y = rng.standard_normal(8)
In [156]: x
Out[156]:
array([-1.3678, 0.6489, 0.3611, -1.9529, 2.3474, 0.9685, -0.7594,
0.9022])
In [157]: y
Out[157]:
array([-0.467 , -0.0607, 0.7888, -1.2567, 0.5759, 1.399 , 1.3223,
-0.2997])
In [158]: np.maximum(x, y)
Out[158]:
array([-0.467 , 0.6489, 0.7888, -1.2567, 2.3474, 1.399 , 1.3223,
0.9022])在此示例中,numpy.maximum 计算 x 和 y 中元素的逐元素最大值。
虽然不常见,但 ufunc 可以返回多个数组。numpy.modf 是一个示例:内置 Python math.modf 的矢量化版本,它返回浮点数组的小数部分和整数部分:
In [159]: arr = rng.standard_normal(7) * 5
In [160]: arr
Out[160]: array([ 4.5146, -8.1079, -0.7909, 2.2474, -6.718 , -0.4084, 8.6237])
In [161]: remainder, whole_part = np.modf(arr)
In [162]: remainder
Out[162]: array([ 0.5146, -0.1079, -0.7909, 0.2474, -0.718 , -0.4084, 0.6237])
In [163]: whole_part
Out[163]: array([ 4., -8., -0., 2., -6., -0., 8.])Ufunc 接受一个可选的 out 参数,该参数允许它们将结果分配到现有数组中,而不是创建一个新数组:
In [164]: arr
Out[164]: array([ 4.5146, -8.1079, -0.7909, 2.2474, -6.718 , -0.4084, 8.6237])
In [165]: out = np.zeros_like(arr)
In [166]: np.add(arr, 1)
Out[166]: array([ 5.5146, -7.1079, 0.2091, 3.2474, -5.718 , 0.5916, 9.6237])
In [167]: np.add(arr, 1, out=out)
Out[167]: array([ 5.5146, -7.1079, 0.2091, 3.2474, -5.718 , 0.5916, 9.6237])
In [168]: out
Out[168]: array([ 5.5146, -7.1079, 0.2091, 3.2474, -5.718 , 0.5916, 9.6237])请参阅 Table 4.4 和 Table 4.5,了解一些 NumPy ufunc 的列表。新的 ufunc 不断添加到 NumPy 中,因此查阅在线 NumPy 文档是获取全面列表并保持最新状态的最佳方式。
| Function | Description |
|---|---|
abs, fabs |
按元素计算整数、浮点或复数值的绝对值 |
sqrt |
计算每个元素的平方根(相当于arr ** 0.5) |
square |
计算每个元素的平方(相当于 arr ** 2) |
exp |
计算每个元素的指数 \(e^x\) |
log, log10, log2, log1p |
分别为自然对数(以 \(e\) 为底)、以 10 为底的对数、以 2 为底的对数和 log(1 + x) |
sign |
计算每个元素的符号:1(正)、0(零)或 –1(负) |
ceil |
计算每个元素的上限(即大于或等于该数字的最小整数) |
floor |
计算每个元素的下限(即小于或等于每个元素的最大整数) |
rint |
将元素舍入到最接近的整数,保留 dtype |
modf |
将数组的小数部分和整数部分作为单独的数组返回 |
isnan |
返回布尔数组,指示每个值是否为 NaN(非数字) |
isfinite, isinf |
返回布尔数组,分别指示每个元素是有限(non-inf, non-NaN)还是无限 |
cos, cosh, sin, sinh, tan, tanh |
正则和双曲三角函数 |
arccos, arccosh, arcsin, arcsinh, arctan, arctanh |
反三角函数 |
logical_not |
按元素计算 not x 的真值(相当于 ~arr) |
| Function | Description |
|---|---|
add |
添加数组中对应的元素 |
subtract |
从第一个数组中减去第二个数组中的元素 |
multiply |
数组元素相乘 |
divide, floor_divide |
除法或地板除法(截断余数) |
power |
将第一个数组中的元素计算为第二个数组中指示的幂 |
maximum, fmax |
逐元素最大值;fmax 忽略 NaN |
minimum, fmin |
逐元素最小值;fmin 忽略 NaN |
mod |
逐元素模(除法的余数) |
copysign |
将第二个参数中的值的符号复制到第一个参数中的值 |
greater, greater_equal, less, less_equal, equal, not_equal |
执行逐元素比较,生成布尔数组(相当于中缀运算符 >、>=、<、<=、==、!=) |
logical_and |
计算 AND (&) 逻辑运算的逐元素真值 |
logical_or |
计算 OR (|) 逻辑运算的逐元素真值 |
logical_xor |
计算 XOR (^) 逻辑运算的逐元素真值 |
4.4 Array-Oriented Programming with Arrays
使用 NumPy 数组使您能够将多种数据处理任务表示为简洁的数组表达式,否则可能需要编写循环。这种用数组表达式替换显式循环的做法被一些人称为矢量化(vectorization)。一般来说,矢量化数组运算通常比纯 Python 运算要快得多,这对任何类型的数值计算都有最大的影响。随后,在 Appendix A: Advanced NumPy 中,我解释了广播(broadcasting),这是一种用于矢量化计算的强大方法。
举一个简单的例子,假设我们希望在规则的值网格上计算函数 sqrt(x^2 + y^2)。numpy.meshgrid 函数接受两个一维数组并生成两个二维矩阵,对应于这两个数组中的所有 (x, y) 对:
In [169]: points = np.arange(-5, 5, 0.01) # 100 equally spaced points
In [170]: xs, ys = np.meshgrid(points, points)
In [171]: ys
Out[171]:
array([[-5. , -5. , -5. , ..., -5. , -5. , -5. ],
[-4.99, -4.99, -4.99, ..., -4.99, -4.99, -4.99],
[-4.98, -4.98, -4.98, ..., -4.98, -4.98, -4.98],
...,
[ 4.97, 4.97, 4.97, ..., 4.97, 4.97, 4.97],
[ 4.98, 4.98, 4.98, ..., 4.98, 4.98, 4.98],
[ 4.99, 4.99, 4.99, ..., 4.99, 4.99, 4.99]])现在,评估函数只需编写与使用两点编写的相同表达式:
In [172]: z = np.sqrt(xs ** 2 + ys ** 2)
In [173]: z
Out[173]:
array([[7.0711, 7.064 , 7.0569, ..., 7.0499, 7.0569, 7.064 ],
[7.064 , 7.0569, 7.0499, ..., 7.0428, 7.0499, 7.0569],
[7.0569, 7.0499, 7.0428, ..., 7.0357, 7.0428, 7.0499],
...,
[7.0499, 7.0428, 7.0357, ..., 7.0286, 7.0357, 7.0428],
[7.0569, 7.0499, 7.0428, ..., 7.0357, 7.0428, 7.0499],
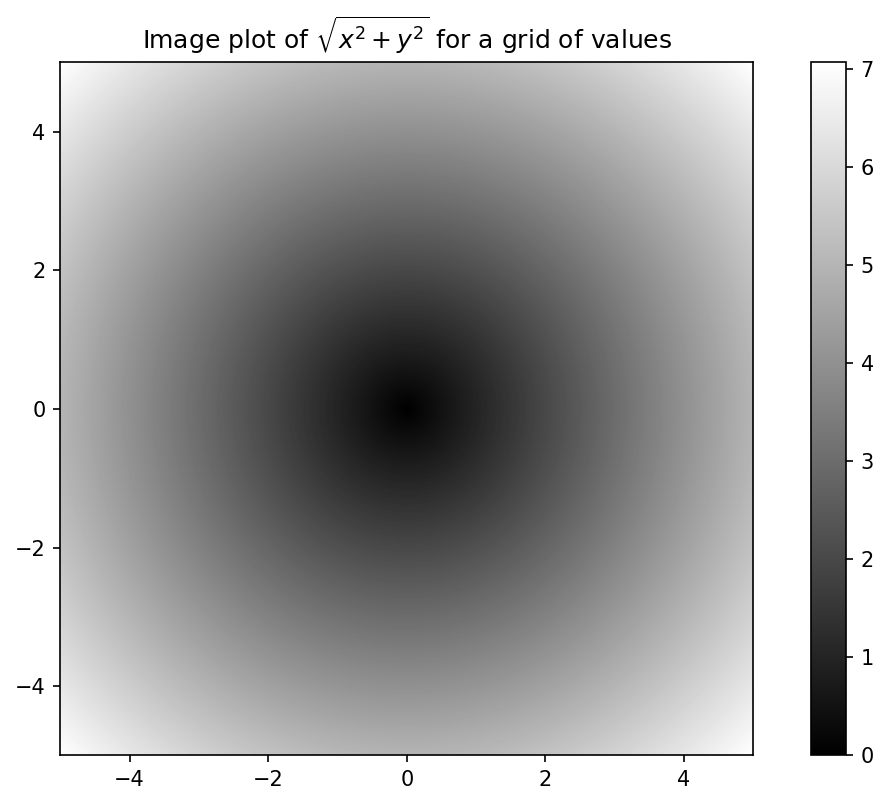
[7.064 , 7.0569, 7.0499, ..., 7.0428, 7.0499, 7.0569]])作为 Ch 9: Plotting and Visualization 的预览,我使用 matplotlib 创建此二维数组的可视化:
In [174]: import matplotlib.pyplot as plt
In [175]: plt.imshow(z, cmap=plt.cm.gray, extent=[-5, 5, -5, 5])
Out[175]: <matplotlib.image.AxesImage at 0x17f04b040>
In [176]: plt.colorbar()
Out[176]: <matplotlib.colorbar.Colorbar at 0x1810661a0>
In [177]: plt.title("Image plot of $\sqrt{x^2 + y^2}$ for a grid of values")
Out[177]: Text(0.5, 1.0, 'Image plot of $\\sqrt{x^2 + y^2}$ for a grid of values'
)在 Plot of function evaluated on a grid 中,我使用 matplotlib 函数 imshow 从函数值的二维数组创建图像图。
如果您使用 IPython,则可以通过执行 plt.close("all") 关闭所有打开的绘图窗口:
In [179]: plt.close("all")术语矢量化(vectorization)用于描述其他一些计算机科学概念,但在本书中,我使用它来描述一次对整个数据数组的操作,而不是使用 Python for 循环逐个值进行操作。
4.4.1 Expressing Conditional Logic as Array Operations
numpy.where 函数是三元表达式 x if condition else y 的矢量化版本。假设我们有一个布尔数组和两个值数组:
In [180]: xarr = np.array([1.1, 1.2, 1.3, 1.4, 1.5])
In [181]: yarr = np.array([2.1, 2.2, 2.3, 2.4, 2.5])
In [182]: cond = np.array([True, False, True, True, False])假设我们想在 cond 中对应的值为 True 时从 xarr 中获取值,否则从 yarr 中获取值。执行此操作的列表理解可能如下所示:
In [183]: result = [(x if c else y)
.....: for x, y, c in zip(xarr, yarr, cond)]
In [184]: result
Out[184]: [1.1, 2.2, 1.3, 1.4, 2.5]这有多个问题。首先,对于大型数组来说,它不会很快(因为所有工作都是在解释的 Python 代码中完成的)。其次,它不适用于多维数组。使用 numpy.where 您可以通过单个函数调用来完成此操作:
In [185]: result = np.where(cond, xarr, yarr)
In [186]: result
Out[186]: array([1.1, 2.2, 1.3, 1.4, 2.5])numpy.where 的第二个和第三个参数不需要是数组;它们之一或两者都可以是标量。数据分析中 where 的典型用途是根据另一个数组生成一个新的值数组。假设您有一个随机生成的数据矩阵,并且您希望将所有正值替换为 2,将所有负值替换为 –2。这可以通过 numpy.where 来完成:
In [187]: arr = rng.standard_normal((4, 4))
In [188]: arr
Out[188]:
array([[ 2.6182, 0.7774, 0.8286, -0.959 ],
[-1.2094, -1.4123, 0.5415, 0.7519],
[-0.6588, -1.2287, 0.2576, 0.3129],
[-0.1308, 1.27 , -0.093 , -0.0662]])
In [189]: arr > 0
Out[189]:
array([[ True, True, True, False],
[False, False, True, True],
[False, False, True, True],
[False, True, False, False]])
In [190]: np.where(arr > 0, 2, -2)
Out[190]:
array([[ 2, 2, 2, -2],
[-2, -2, 2, 2],
[-2, -2, 2, 2],
[-2, 2, -2, -2]])使用 numpy.where 时可以组合标量和数组。例如,我可以将 arr 中的所有正值替换为常数 2,如下所示:
In [191]: np.where(arr > 0, 2, arr) # set only positive values to 2
Out[191]:
array([[ 2. , 2. , 2. , -0.959 ],
[-1.2094, -1.4123, 2. , 2. ],
[-0.6588, -1.2287, 2. , 2. ],
[-0.1308, 2. , -0.093 , -0.0662]])4.4.2 Mathematical and Statistical Methods
一组数学函数,用于计算整个数组或沿轴的数据的统计数据,可作为数组类的方法进行访问。您可以通过调用数组实例方法或使用顶级 NumPy 函数来使用聚合(有时称为缩减),例如 sum、mean 和 std(标准差)。当您使用 NumPy 函数(如 numpy.sum)时,您必须传递要聚合的数组作为第一个参数。
在这里,我生成一些正态分布的随机数据并计算一些聚合统计数据:
In [192]: arr = rng.standard_normal((5, 4))
In [193]: arr
Out[193]:
array([[-1.1082, 0.136 , 1.3471, 0.0611],
[ 0.0709, 0.4337, 0.2775, 0.5303],
[ 0.5367, 0.6184, -0.795 , 0.3 ],
[-1.6027, 0.2668, -1.2616, -0.0713],
[ 0.474 , -0.4149, 0.0977, -1.6404]])
In [194]: arr.mean()
Out[194]: -0.08719744457434529
In [195]: np.mean(arr)
Out[195]: -0.08719744457434529
In [196]: arr.sum()
Out[196]: -1.743948891486906像 mean 和 sum 这样的函数采用一个可选的轴参数来计算给定轴上的统计数据,从而产生一个少一维的数组:
In [197]: arr.mean(axis=1)
Out[197]: array([ 0.109 , 0.3281, 0.165 , -0.6672, -0.3709])
In [198]: arr.sum(axis=0)
Out[198]: array([-1.6292, 1.0399, -0.3344, -0.8203])此处,arr.mean(axis=1) 表示“计算各列的平均值”,其中 arr.sum(axis=0) 表示“计算各行的总和”。
其他方法(如 cumsum 和 cumprod)不会聚合,而是生成中间结果数组:
In [199]: arr = np.array([0, 1, 2, 3, 4, 5, 6, 7])
In [200]: arr.cumsum()
Out[200]: array([ 0, 1, 3, 6, 10, 15, 21, 28])在多维数组中,像 cumsum 这样的累积函数返回一个大小相同的数组,但根据每个较低维度的切片沿指示轴计算部分聚合:
In [201]: arr = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
In [202]: arr
Out[202]:
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])表达式 arr.cumsum(axis=0) 计算沿行的累积总和,而 arr.cumsum(axis=1) 计算沿列的总和:
In [203]: arr.cumsum(axis=0)
Out[203]:
array([[ 0, 1, 2],
[ 3, 5, 7],
[ 9, 12, 15]])
In [204]: arr.cumsum(axis=1)
Out[204]:
array([[ 0, 1, 3],
[ 3, 7, 12],
[ 6, 13, 21]])完整列表请参见 Table 4.6。我们将在后面的章节中看到这些方法的许多实际例子。
| Method | Description |
|---|---|
sum |
数组中或沿轴的所有元素的总和;零长度数组的总和为 0 |
mean |
算术平均值;对零长度数组无效(返回 NaN) |
std, var |
分别为标准差和方差 |
min, max |
最小值和最大值 |
argmin, argmax |
分别是最小和最大元素的索引 |
cumsum |
从0开始的元素累加和 |
cumprod |
从1开始的元素的累积乘积 |
4.4.3 Methods for Boolean Arrays
在前面的方法中,布尔值被强制为 1 (True) 和 0 (False)。因此,sum 通常用作计算布尔数组中 True 值的方法:
In [205]: arr = rng.standard_normal(100)
In [206]: (arr > 0).sum() # Number of positive values
Out[206]: 48
In [207]: (arr <= 0).sum() # Number of non-positive values
Out[207]: 52表达式 (arr > 0).sum() 中的括号是能够对 arr > 0 的临时结果调用 sum() 所必需的。
两个附加方法,any 和 all,对于布尔数组尤其有用。any 测试数组中的一个或多个值是否为 True,而 all 则检查每个值是否为 True:
In [208]: bools = np.array([False, False, True, False])
In [209]: bools.any()
Out[209]: True
In [210]: bools.all()
Out[210]: False这些方法也适用于非布尔数组,其中非零元素被视为 True。
4.4.4 Sorting
与 Python 的内置列表类型一样,NumPy 数组可以使用 sort 方法就地排序:
In [211]: arr = rng.standard_normal(6)
In [212]: arr
Out[212]: array([ 0.0773, -0.6839, -0.7208, 1.1206, -0.0548, -0.0824])
In [213]: arr.sort()
In [214]: arr
Out[214]: array([-0.7208, -0.6839, -0.0824, -0.0548, 0.0773, 1.1206])您可以通过传递要排序的轴编号,沿轴对多维数组中值的每个一维部分进行排序。本例中的数据:
In [215]: arr = rng.standard_normal((5, 3))
In [216]: arr
Out[216]:
array([[ 0.936 , 1.2385, 1.2728],
[ 0.4059, -0.0503, 0.2893],
[ 0.1793, 1.3975, 0.292 ],
[ 0.6384, -0.0279, 1.3711],
[-2.0528, 0.3805, 0.7554]])arr.sort(axis=0) 对每列中的值进行排序,而 arr.sort(axis=1) 对每行进行排序:
In [217]: arr.sort(axis=0)
In [218]: arr
Out[218]:
array([[-2.0528, -0.0503, 0.2893],
[ 0.1793, -0.0279, 0.292 ],
[ 0.4059, 0.3805, 0.7554],
[ 0.6384, 1.2385, 1.2728],
[ 0.936 , 1.3975, 1.3711]])
In [219]: arr.sort(axis=1)
In [220]: arr
Out[220]:
array([[-2.0528, -0.0503, 0.2893],
[-0.0279, 0.1793, 0.292 ],
[ 0.3805, 0.4059, 0.7554],
[ 0.6384, 1.2385, 1.2728],
[ 0.936 , 1.3711, 1.3975]])顶级方法 numpy.sort 返回数组的排序副本(如 Python 内置函数 sorted),而不是就地修改数组。例如:
In [221]: arr2 = np.array([5, -10, 7, 1, 0, -3])
In [222]: sorted_arr2 = np.sort(arr2)
In [223]: sorted_arr2
Out[223]: array([-10, -3, 0, 1, 5, 7])有关使用 NumPy 排序方法以及间接排序等更高级技术的更多详细信息,请参阅 Appendix A: Advanced NumPy。pandas 中还可以找到与排序相关的其他几种数据操作(例如,按一列或多列对数据表进行排序)。
4.4.5 Unique and Other Set Logic
NumPy 对一维 ndarray 有一些基本的集合运算。常用的是 numpy.unique,它返回数组中排序后的唯一值:
In [224]: names = np.array(["Bob", "Will", "Joe", "Bob", "Will", "Joe", "Joe"])
In [225]: np.unique(names)
Out[225]: array(['Bob', 'Joe', 'Will'], dtype='<U4')
In [226]: ints = np.array([3, 3, 3, 2, 2, 1, 1, 4, 4])
In [227]: np.unique(ints)
Out[227]: array([1, 2, 3, 4])将 numpy.unique 与纯 Python 替代方案进行对比:
In [228]: sorted(set(names))
Out[228]: ['Bob', 'Joe', 'Will']在许多情况下,NumPy 版本速度更快,并且返回 NumPy 数组而不是 Python 列表。
另一个函数 numpy.in1d 测试一个数组中的值在另一个数组中的成员资格,返回一个布尔数组:
In [229]: values = np.array([6, 0, 0, 3, 2, 5, 6])
In [230]: np.in1d(values, [2, 3, 6])
Out[230]: array([ True, False, False, True, True, False, True])有关 NumPy 中数组集合运算的列表,请参阅 Table 4.7。
| Method | Description |
|---|---|
unique(x) |
计算 x 中已排序的唯一元素 |
intersect1d(x, y) |
计算 x 和 y 中已排序的公共元素 |
union1d(x, y) |
计算元素的排序并集 |
in1d(x, y) |
计算一个布尔数组,指示 x 的每个元素是否包含在 y 中 |
setdiff1d(x, y) |
设置差异,x 中不在 y 中的元素 |
setxor1d(x, y) |
设置对称差异;元素存在于任一数组中,但不能同时存在于两个数组中 |
4.5 File Input and Output with Arrays
NumPy 能够以某些文本或二进制格式将数据保存到磁盘或从磁盘加载数据。在本节中,我仅讨论 NumPy 的内置二进制格式,因为大多数用户更喜欢 pandas 和其他工具来加载文本或表格数据(有关更多信息,请参阅 Ch 6: Data Loading, Storage, and File Formats)。
numpy.save 和 numpy.load 是在磁盘上高效保存和加载数组数据的两个主力函数。数组默认以未压缩的原始二进制格式保存,文件扩展名为 .npy:
In [231]: arr = np.arange(10)
In [232]: np.save("some_array", arr)如果文件路径尚未以 .npy 结尾,则会附加扩展名。然后可以使用 numpy.load 加载磁盘上的数组:
In [233]: np.load("some_array.npy")
Out[233]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])您可以使用 numpy.savez 将多个数组保存在未压缩的存档中,并将数组作为关键字参数传递:
In [234]: np.savez("array_archive.npz", a=arr, b=arr)加载 .npz 文件时,您会返回一个类似字典的对象,该对象会延迟加载各个数组:
In [235]: arch = np.load("array_archive.npz")
In [236]: arch["b"]
Out[236]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])如果你的数据压缩得很好,你可能希望使用 numpy.savez_compressed 代替:
In [237]: np.savez_compressed("arrays_compressed.npz", a=arr, b=arr)4.6 Linear Algebra
线性代数运算,如矩阵乘法、分解、行列式和其他方阵数学,是许多数组库的重要组成部分。将两个二维数组与 * 相乘是逐元素乘积,而矩阵乘法需要使用 dot 函数或 @ 中缀运算符。dot 既是一个数组方法,也是 numpy 命名空间中用于进行矩阵乘法的函数:
In [241]: x = np.array([[1., 2., 3.], [4., 5., 6.]])
In [242]: y = np.array([[6., 23.], [-1, 7], [8, 9]])
In [243]: x
Out[243]:
array([[1., 2., 3.],
[4., 5., 6.]])
In [244]: y
Out[244]:
array([[ 6., 23.],
[-1., 7.],
[ 8., 9.]])
In [245]: x.dot(y)
Out[245]:
array([[ 28., 64.],
[ 67., 181.]])x.dot(y) 等价于 np.dot(x, y):
In [246]: np.dot(x, y)
Out[246]:
array([[ 28., 64.],
[ 67., 181.]])二维数组和适当大小的一维数组之间的矩阵乘积会生成一维数组:
In [247]: x @ np.ones(3)
Out[247]: array([ 6., 15.])numpy.linalg 有一组标准的矩阵分解以及逆矩阵和行列式等:
In [248]: from numpy.linalg import inv, qr
In [249]: X = rng.standard_normal((5, 5))
In [250]: mat = X.T @ X
In [251]: inv(mat)
Out[251]:
array([[ 3.4993, 2.8444, 3.5956, -16.5538, 4.4733],
[ 2.8444, 2.5667, 2.9002, -13.5774, 3.7678],
[ 3.5956, 2.9002, 4.4823, -18.3453, 4.7066],
[-16.5538, -13.5774, -18.3453, 84.0102, -22.0484],
[ 4.4733, 3.7678, 4.7066, -22.0484, 6.0525]])
In [252]: mat @ inv(mat)
Out[252]:
array([[ 1., 0., 0., 0., 0.],
[ 0., 1., 0., 0., 0.],
[ 0., 0., 1., -0., 0.],
[ 0., 0., 0., 1., 0.],
[-0., 0., 0., 0., 1.]])表达式 X.T.dot(X) 计算 X 与其转置 X.T 的点积。
请参阅 Table 4.8,了解一些最常用的线性代数函数的列表。
| Function | Description |
|---|---|
diag |
将方阵的对角线(或非对角线)元素作为一维数组返回,或将一维数组转换为非对角线为零的方阵 |
dot |
矩阵乘法 |
trace |
计算对角线元素的总和 |
det |
计算矩阵行列式 |
eig |
计算方阵的特征值和特征向量 |
inv |
计算方阵的逆矩阵 |
pinv |
计算矩阵的 Moore-Penrose 伪逆 |
qr |
计算 QR 分解 |
svd |
计算奇异值分解 (SVD) |
solve |
求解线性方程组 Ax = b for x,其中 A 是方阵 |
lstsq |
计算 Ax = b 的最小二乘解 |
4.7 Example: Random Walks
random walks 的模拟提供了利用数组操作的说明性应用。我们首先考虑一个从 0 开始的简单随机游走,步长为 1 和 –1 的概率相等。
下面是使用内置 random 模块实现 1,000 步的单次随机游走的纯 Python 方法:
#! blockstart
import random
position = 0
walk = [position]
nsteps = 1000
for _ in range(nsteps):
step = 1 if random.randint(0, 1) else -1
position += step
walk.append(position)
#! blockend有关这些随机游走之一的前 100 个值的示例图,请参见 Figure 4.4:
In [255]: plt.plot(walk[:100])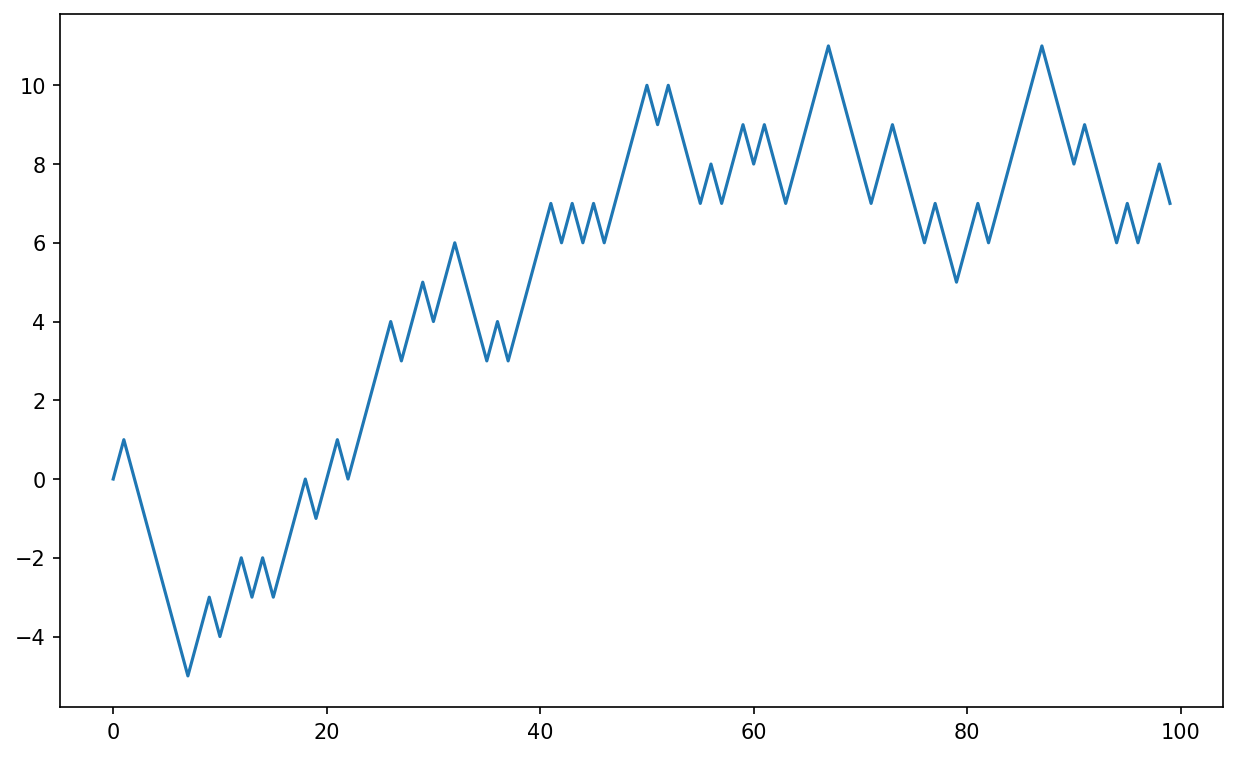
您可能会发现 walk 是随机步骤的累积和,并且可以作为数组表达式进行计算。因此,我使用 numpy.random 模块一次抽取 1,000 次硬币翻转,将它们设置为 1 和 –1,并计算累积和:
In [256]: nsteps = 1000
In [257]: rng = np.random.default_rng(seed=12345) # fresh random generator
In [258]: draws = rng.integers(0, 2, size=nsteps)
In [259]: steps = np.where(draws == 0, 1, -1)
In [260]: walk = steps.cumsum()由此我们可以开始提取统计数据,例如步行轨迹上的最小值和最大值:
In [261]: walk.min()
Out[261]: -8
In [262]: walk.max()
Out[262]: 50更复杂的统计数据是第一次交叉时间,即随机游走达到特定值的步骤。这里我们可能想知道随机游走在任一方向上距离原点 0 至少 10 步需要多长时间。np.abs(walk) >= 10 为我们提供了一个布尔数组,指示步行已达到或超过 10,但我们需要前 10 或 –10 的索引。事实证明,我们可以使用 argmax 来计算它,它返回布尔数组中最大值的第一个索引(True 是最大值):
In [263]: (np.abs(walk) >= 10).argmax()
Out[263]: 155请注意,此处使用 argmax 并不总是有效,因为它总是对数组进行完整扫描。在这种特殊情况下,一旦观察到 True,我们就知道它是最大值。
4.7.1 Simulating Many Random Walks at Once
如果您的目标是模拟许多随机游走,例如 5000 次,则只需对前面的代码进行少量修改即可生成所有随机游走。如果传递一个 2 元组,numpy.random 函数将生成一个二维绘图数组,我们可以计算每一行的累积和,从而一次计算所有 5000 个随机游走:
In [264]: nwalks = 5000
In [265]: nsteps = 1000
In [266]: draws = rng.integers(0, 2, size=(nwalks, nsteps)) # 0 or 1
In [267]: steps = np.where(draws > 0, 1, -1)
In [268]: walks = steps.cumsum(axis=1)
In [269]: walks
Out[269]:
array([[ 1, 2, 3, ..., 22, 23, 22],
[ 1, 0, -1, ..., -50, -49, -48],
[ 1, 2, 3, ..., 50, 49, 48],
...,
[ -1, -2, -1, ..., -10, -9, -10],
[ -1, -2, -3, ..., 8, 9, 8],
[ -1, 0, 1, ..., -4, -3, -2]])现在,我们可以计算所有行走中获得的最大值和最小值:
In [270]: walks.max()
Out[270]: 114
In [271]: walks.min()
Out[271]: -120在这些步行中,我们计算最短的穿越时间为 30 或 –30。这有点棘手,因为并非所有 5,000 个都达到 30。我们可以使用 any 方法检查这一点:
In [272]: hits30 = (np.abs(walks) >= 30).any(axis=1)
In [273]: hits30
Out[273]: array([False, True, True, ..., True, False, True])
In [274]: hits30.sum() # Number that hit 30 or -30
Out[274]: 3395我们可以使用这个布尔数组来选择实际穿过绝对 30 层的 walks 行,并跨轴 1 调用 argmax 来获取交叉时间:
In [275]: crossing_times = (np.abs(walks[hits30]) >= 30).argmax(axis=1)
In [276]: crossing_times
Out[276]: array([201, 491, 283, ..., 219, 259, 541])最后,我们计算平均最短穿越时间:
In [277]: crossing_times.mean()
Out[277]: 500.5699558173785除了抛等大小的硬币之外,请随意尝试其他分布的步骤。您只需要使用不同的随机生成器方法,例如 standard_normal 来生成具有一定平均值和标准差的正态分布步骤:
In [278]: draws = 0.25 * rng.standard_normal((nwalks, nsteps))请记住,这种矢量化方法需要创建一个包含 nwalks * nsteps 元素的数组,这可能会使用大量内存进行大型模拟。如果内存更受限制,则需要采用不同的方法。
4.8 Conclusion
虽然本书的其余部分将重点关注如何使用 pandas 构建数据整理技能,但我们将继续以类似的基于数组的风格进行工作。在 Appendix A: Advanced NumPy 中,我们将深入探讨 NumPy 功能,以帮助您进一步发展数组计算技能。