# 安装包
if (!requireNamespace("ggseqlogo", quietly = TRUE)) {
install.packages("ggseqlogo")
}
if (!requireNamespace("ggplot2", quietly = TRUE)) {
install.packages("ggplot2")
}
# 加载包
library(ggseqlogo)
library(ggplot2)序列 Logo
注记
Hiplot 网站
本页面为 Hiplot Seqlogo 插件的源码版本教程,您也可以使用 Hiplot 网站实现无代码绘图,更多信息请查看以下链接:
序列 Logo 是一种用来描述结合位点序列模式的图形。
环境配置
系统: Cross-platform (Linux/MacOS/Windows)
编程语言: R
依赖包:
ggseqlogo;ggplot2
数据准备
载入数据为多个转录因子在多个基因上的结合位点的序列。
# 加载数据
data <- read.delim("files/Hiplot/074-ggseqlogo-data.txt", header = T)
# 整理数据格式
data <- data[, !sapply(data, function(x) {all(is.na(x))})]
data <- as.list(data)
data <- lapply(data, function(x) {return(x[!is.na(x)])})
# 查看数据
str(data)List of 12
$ MA0001.1: chr [1:97] "CCATATATAG" "CCATATATAG" "CCATAAATAG" "CCATAAATAG" ...
$ MA0002.1: chr [1:26] "AATTGTGGTTA" "ATCTGTGGTTA" "AATTGTGGTAA" "TTCTGCGGTTA" ...
$ MA0004.1: chr [1:20] "CACGTG" "CACGTG" "CACGTG" "CACGTG" ...
$ MA0005.1: chr [1:90] "CCTAATTGGGC" "CCTAATTTGGC" "CCTAATCGGGC" "CCTAATCGGGC" ...
$ MA0006.1: chr [1:24] "CGCGTG" "CGCGTG" "CGCGTG" "CGCGTG" ...
$ MA0007.1: chr [1:24] "AAAAGTACACCCTGTACCGACA" "CTAAGCACACCGTGTCCCAGTC" "TTAAGAACACTCTGTACGACAC" "AGTAGAACATAATGTTCCGACA" ...
$ MA0008.1: chr [1:25] "CAATTATT" "CAATTATT" "CAATTATT" "CAATTATT" ...
$ MA0009.1: chr [1:40] "CTAGGTGTGAA" "CTAGGTGTGAA" "CTAGGTGTGAA" "CTAGGTGTGAA" ...
$ MA0010.1: chr [1:9] "CTAATTGGCAAATG" "ATAATAAACAAAAC" "GACATAGACAAGAC" "GTCTTTCACAAATA" ...
$ MA0011.1: chr [1:12] "AACTATTT" "TGCTAGTT" "TCCTAGTT" "TTCTATTC" ...
$ MA0012.1: chr [1:12] "TAAACTTGTTG" "TAAACTAAAGC" "TCAACTAGGAT" "TAAACAAAACC" ...
$ MA0013.1: chr [1:6] "TTGTGAAAGAC" "AAGTAAACTAA" "TAATAAACAAA" "TAATAAACAAA" ...可视化
# 序列 Logo
p <- ggseqlogo(
data,
ncol = 4,
col_scheme = "nucleotide",
seq_type = "dna",
method = "bits") +
theme(plot.title = element_text(hjust = 0.5))
p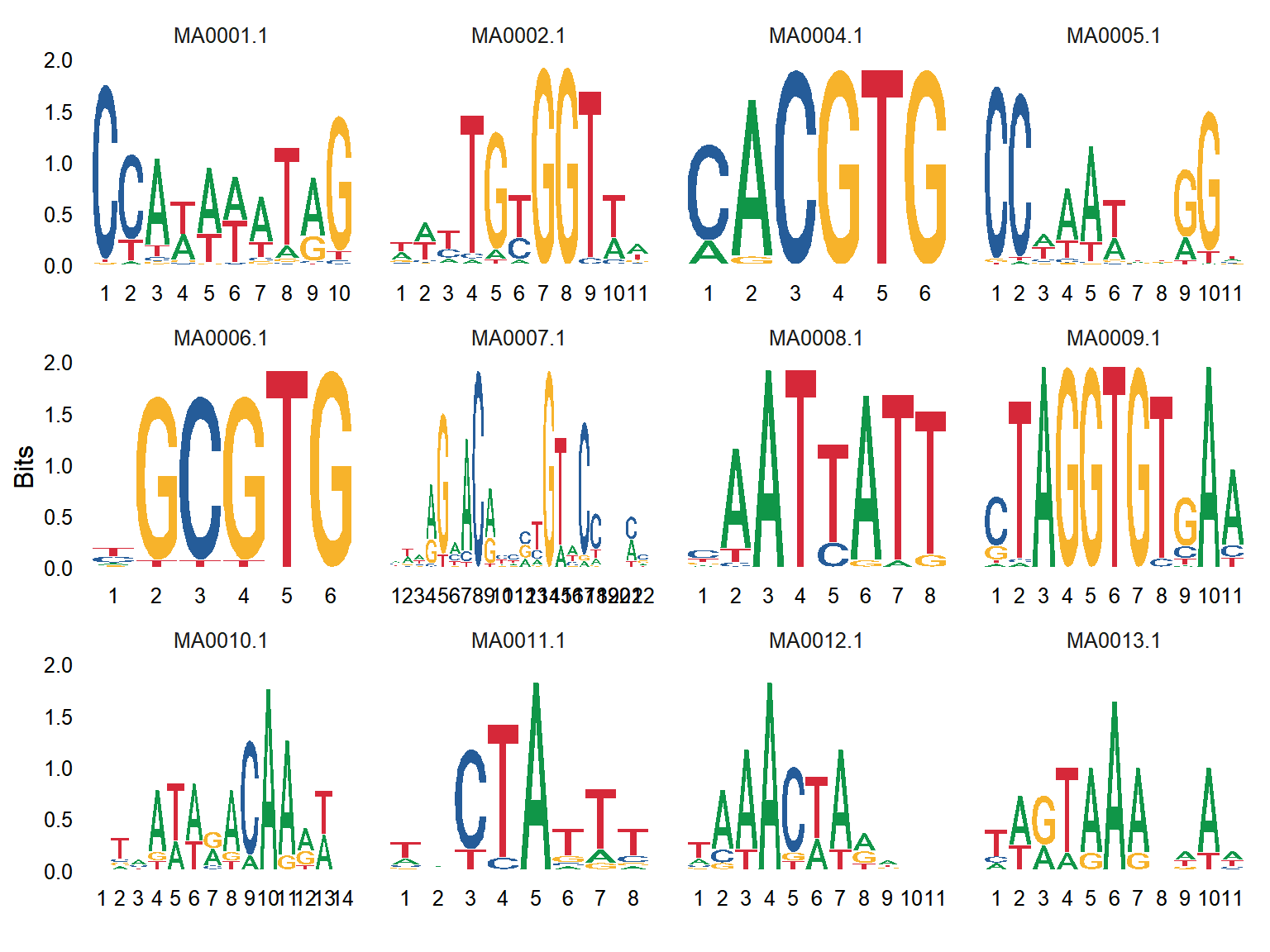
采用 bits 计算的方式将一个结合位点序列展示在图表一列,可以清晰观测到不同序列占比较大的碱基。