# 安装包
if (!requireNamespace("tidyverse", quietly = TRUE)) {
install.packages("tidyverse")
}
if (!requireNamespace("readr", quietly = TRUE)) {
install.packages("readr")
}
if (!requireNamespace("ggalluvial", quietly = TRUE)) {
install.packages("ggalluvial")
}
if (!requireNamespace("patchwork", quietly = TRUE)) {
install.packages("patchwork")
}
# 加载包
library(tidyverse)
library(readr)
library(ggalluvial)
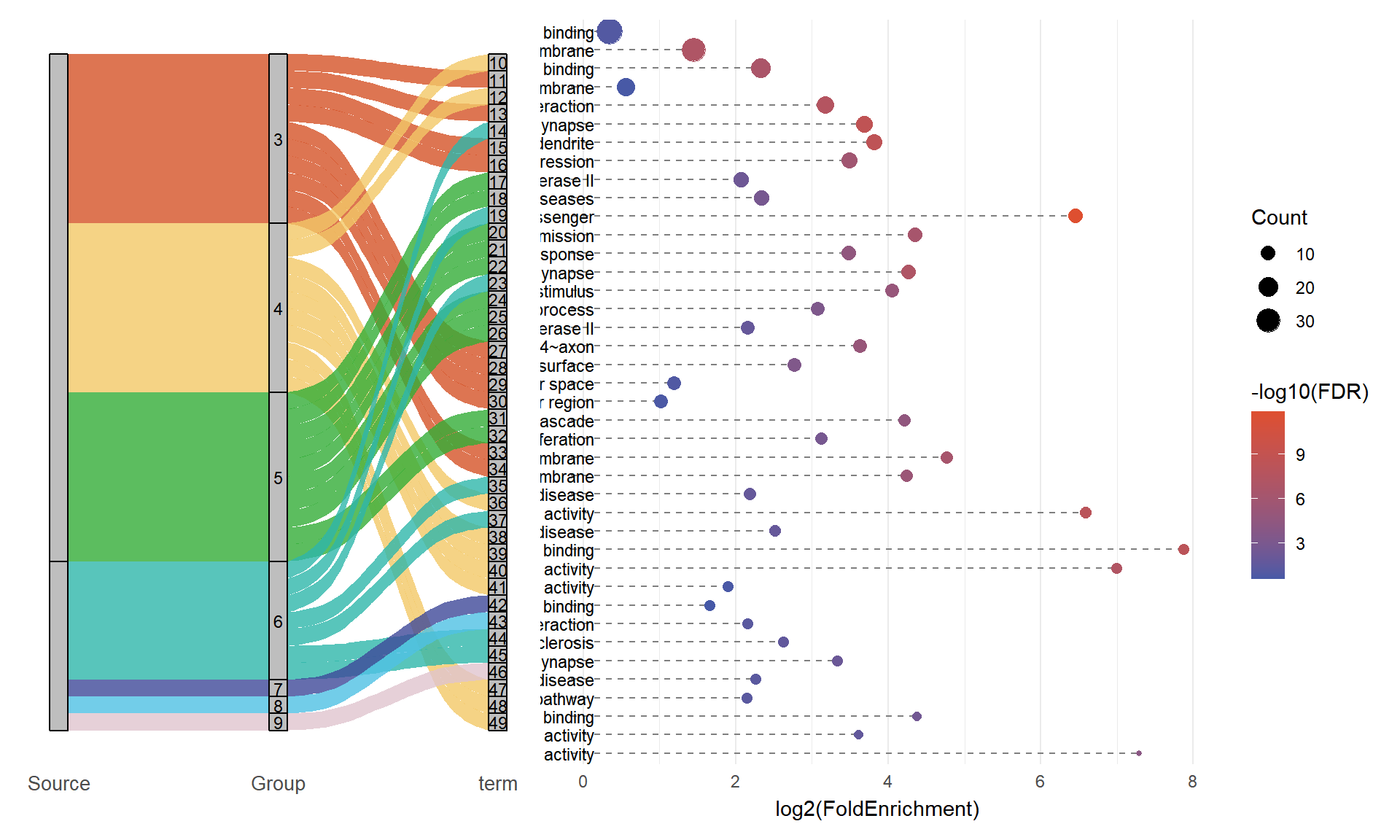
library(patchwork)组合桑基气泡图
示例
环境配置
系统: 跨平台(Linux/MacOS/Windows)
编程语言: R
依赖包:
tidyverse;readr;ggalluvial;patchwork
数据准备
我们导入来自 DAVID 的网络药理学注释分析通路富集数据。
# 读取数据
data <- read_tsv("files/DAVID.txt")
# 添加新分类列
get_category <- function(cat) {
if (grepl("BP", cat)) return("BP")
if (grepl("MF", cat)) return("MF")
if (grepl("CC", cat)) return("CC")
if (grepl("KEGG", cat)) return("KEGG")
return(NA)
}
data$MainCategory <- sapply(data$Category, get_category)
# 剔除 SMART 和 NA
data2 <- data %>%
filter(!grepl("SMART", Category)) %>%
filter(!is.na(MainCategory))
# 每类排序并取前10
topN <- function(data, n=10) {
data %>%
arrange(desc(Count), PValue) %>%
head(n)
}
result <- data2 %>%
group_by(MainCategory) %>%
group_modify(~topN(.x, 10)) %>%
ungroup()
# KEGG 通路注释
result <- result %>%
mutate(
Source = ifelse(MainCategory == "KEGG", "KEGG", "GO"),
KEGG_Group = case_when(
MainCategory == "KEGG" & str_detect(Term,"Neuro|synapse|neurodegeneration|Alzheimer|Parkinson|Prion") ~ "Nervous system",
MainCategory == "KEGG" & str_detect(Term, "Cytokine|inflammatory") ~ "Immune system",
MainCategory == "KEGG" & str_detect(Term, "Lipid|atherosclerosis") ~ "Lipid metabolism",
MainCategory == "KEGG" ~ "Other KEGG",
TRUE ~ NA_character_
),
GO_Group = ifelse(MainCategory != "KEGG", MainCategory, NA)
)
alluvial_data <- result %>%
mutate(
Term = str_replace(Term, "^GO:\\d+~", ""), # 去除 GO 编号
Term = str_replace(Term, "^hsa\\d+:?", "") # 去除 KEGG 编号
)
# GO 部分
go_links <- result %>%
filter(Source == "GO") %>%
transmute(
Source = Source,
Group = GO_Group,
Term = Term,
Count = Count
)
# KEGG 部分
kegg_links <- result %>%
filter(Source == "KEGG") %>%
transmute(
Source = Source,
Group = KEGG_Group,
Term = Term,
Count = Count
)
# 生成桑基图数据
alluvial_data <- result %>%
mutate(Group = ifelse(Source == "KEGG", KEGG_Group, GO_Group)) %>%
select(Source, Group, Term, Count, FDR, FoldEnrichment, MainCategory)
# 确保字符型
alluvial_data$Source <- as.character(alluvial_data$Source)
alluvial_data$Group <- as.character(alluvial_data$Group)
alluvial_data$Term <- as.character(alluvial_data$Term)
# 合并
alluvial_data <- bind_rows(go_links, kegg_links)
# 将 term 列按照 count 值从小到大排列,并且保证气泡图和桑基图的顺序一致
term_levels <- alluvial_data %>%
arrange(Source, Group, desc(Count)) %>%
pull(Term) %>%
unique()
alluvial_data$Term <- factor(alluvial_data$Term, levels = term_levels)
# 查看数据结构
head(alluvial_data, 5)# A tibble: 5 × 4
Source Group Term Count
<chr> <chr> <fct> <dbl>
1 GO BP GO:0010628~positive regulation of gene expression 12
2 GO BP GO:0045944~positive regulation of transcription by RNA pol… 11
3 GO BP GO:0007187~G protein-coupled receptor signaling pathway, c… 10
4 GO BP GO:0007268~chemical synaptic transmission 10
5 GO BP GO:0006954~inflammatory response 10可视化
1. 桑基图
# 桑基图(Term列不显示标签)
# 确保 Group 为字符型且无 NA
alluvial_data$Group <- as.character(alluvial_data$Group)
alluvial_data$Group[is.na(alluvial_data$Group)] <- "Other"
# 计算每个 Group 的总 Count
group_order <- alluvial_data %>%
group_by(Group) %>%
summarise(group_count = sum(Count, na.rm = TRUE)) %>%
arrange(desc(group_count)) %>%
pull(Group)
# 设置 group 为有序因子
alluvial_data$Group <- factor(alluvial_data$Group, levels = group_order)
# 对 Term 列进行排序,设置 term 为有序因子
term_order <- alluvial_data %>%
group_by(Term) %>%
summarise(total_count = sum(Count, na.rm = TRUE)) %>%
arrange(desc(total_count)) %>%
pull(Term)
alluvial_data$Term <- factor(alluvial_data$Term, levels = term_order)
# 重新获取 group 的有序标签
group_labels <- levels(alluvial_data$Group)
group_labels <- c("BP", "MF", "CC", "Nervous system", "Immune system", "Lipid metabolism", "Other KEGG")
term_labels <- levels(alluvial_data$Term)
p1 <- ggplot(
alluvial_data,
aes(axis1 = Source, axis2 = Group, axis3 = Term, y = 1)) +
geom_alluvium(aes(fill = Group), width = 1/12, alpha = 0.8) +
geom_stratum(width = 1/12, fill = "grey", color = "black") +
scale_fill_manual(values = c(
"BP" = "#33ad37","MF" = "#f2c867","CC" = "#d45327",
"Nervous system" = "#2eb6aa", "Immune system" = "#3e4999",
"Lipid metabolism" = "#4fc1e4", "Other KEGG" = "#e0c4ce")) +
geom_text(stat = "stratum", aes(label = ifelse(
after_stat(stratum) %in% group_labels, after_stat(stratum),
ifelse(after_stat(stratum) %in% term_labels, after_stat(stratum), "")
)), size = 3) +
scale_x_discrete(
limits = c("Source", "Group", "Term"),
labels = c("Source", "Group", "term"), expand = c(.05, .05)) +
labs(title = NULL, y = NULL, x = NULL) +
theme_minimal(base_size = 12) +
theme(
axis.title.x = element_blank(),
axis.text.x = element_text(size = 10),
axis.text.y = element_blank(),
axis.ticks.y = element_blank(),
plot.margin = margin(5, 5, 5, 5), # 这里和 p2 保持一致
panel.grid = element_blank()
) +
guides(fill = "none")
p1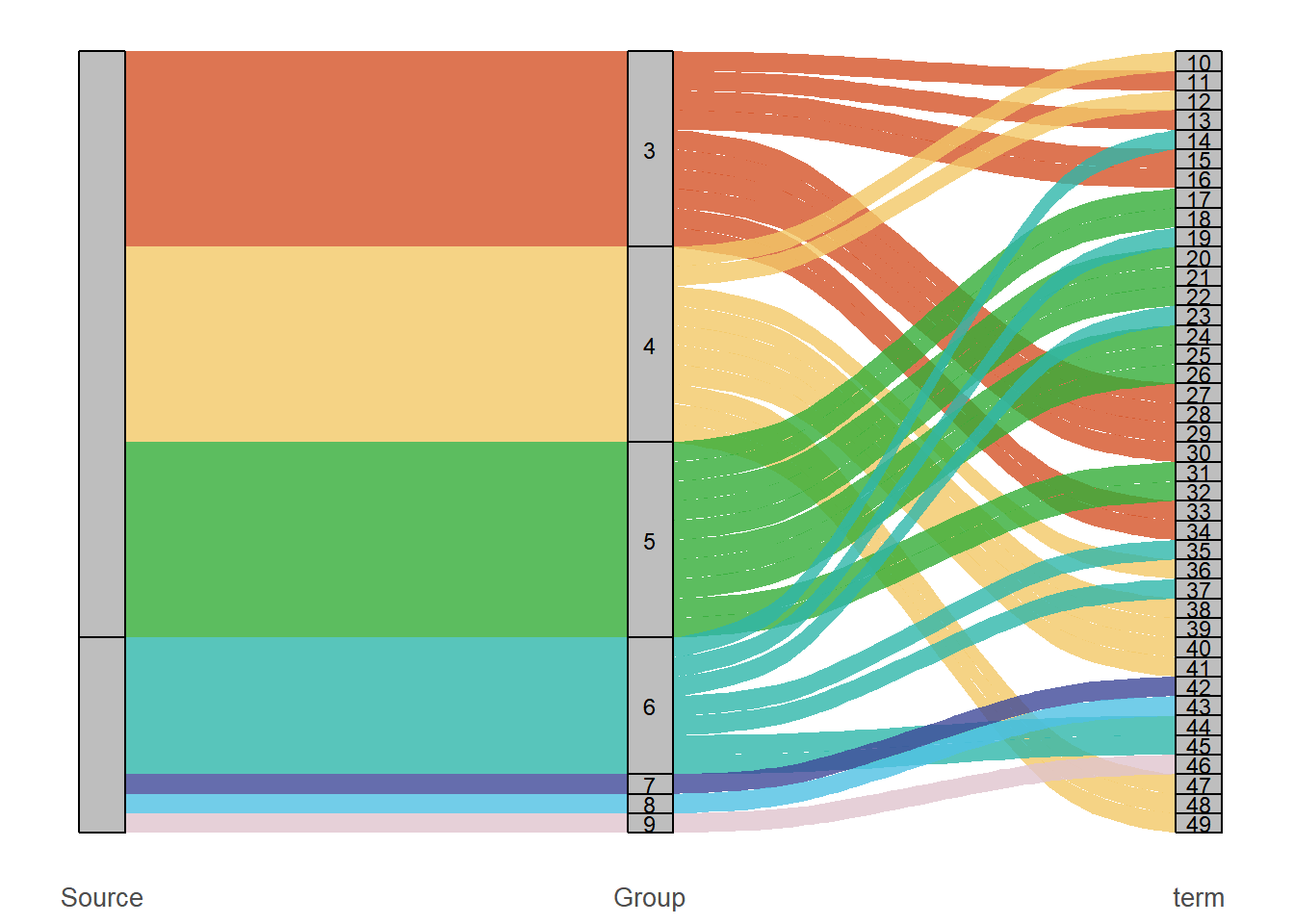
2. 气泡图
# 气泡图(Term标签只在右侧)
# 先准备 term_levels,确保顺序和 y 轴一致
term_levels <- levels(alluvial_data$Term)
# 生成气泡图数据
alluvial_data <- result %>%
mutate(Group = ifelse(Source == "KEGG", KEGG_Group, GO_Group)) %>%
select(Source, Group, Term, Count, FDR, FoldEnrichment, MainCategory)
p2 <- ggplot(alluvial_data, aes(x = log2(FoldEnrichment), y = Term)) +
# 虚线棒:从 x = min_x - offset 到 x = log2(FoldEnrichment)
geom_segment(aes(
x = min(log2(FoldEnrichment), na.rm = TRUE) - 0.5,
xend = log2(FoldEnrichment),
y = Term, yend = Term),
linetype = "dashed", color = "grey50") +
# 左侧标签
geom_text(aes(
x = min(log2(FoldEnrichment), na.rm = TRUE) - 0.2,
label = Term
), hjust = 1, size = 3) +
# 气泡
geom_point(aes(size = Count, color = -log10(FDR))) +
scale_y_discrete(limits = rev(term_levels), position = "right") +
scale_color_gradient(low = "#4659a7", high = "#de4f30") +
labs(title = NULL, x = "log2(FoldEnrichment)", y = NULL, color = "-log10(FDR)") +
theme_minimal() +
theme(
axis.text.y.left = element_blank(),
axis.text.y.right = element_blank(), # 右侧不显示标签
axis.title.y = element_blank(),
plot.margin = margin(5, 5, 5, 0),
panel.grid.major.y = element_blank()
)
p2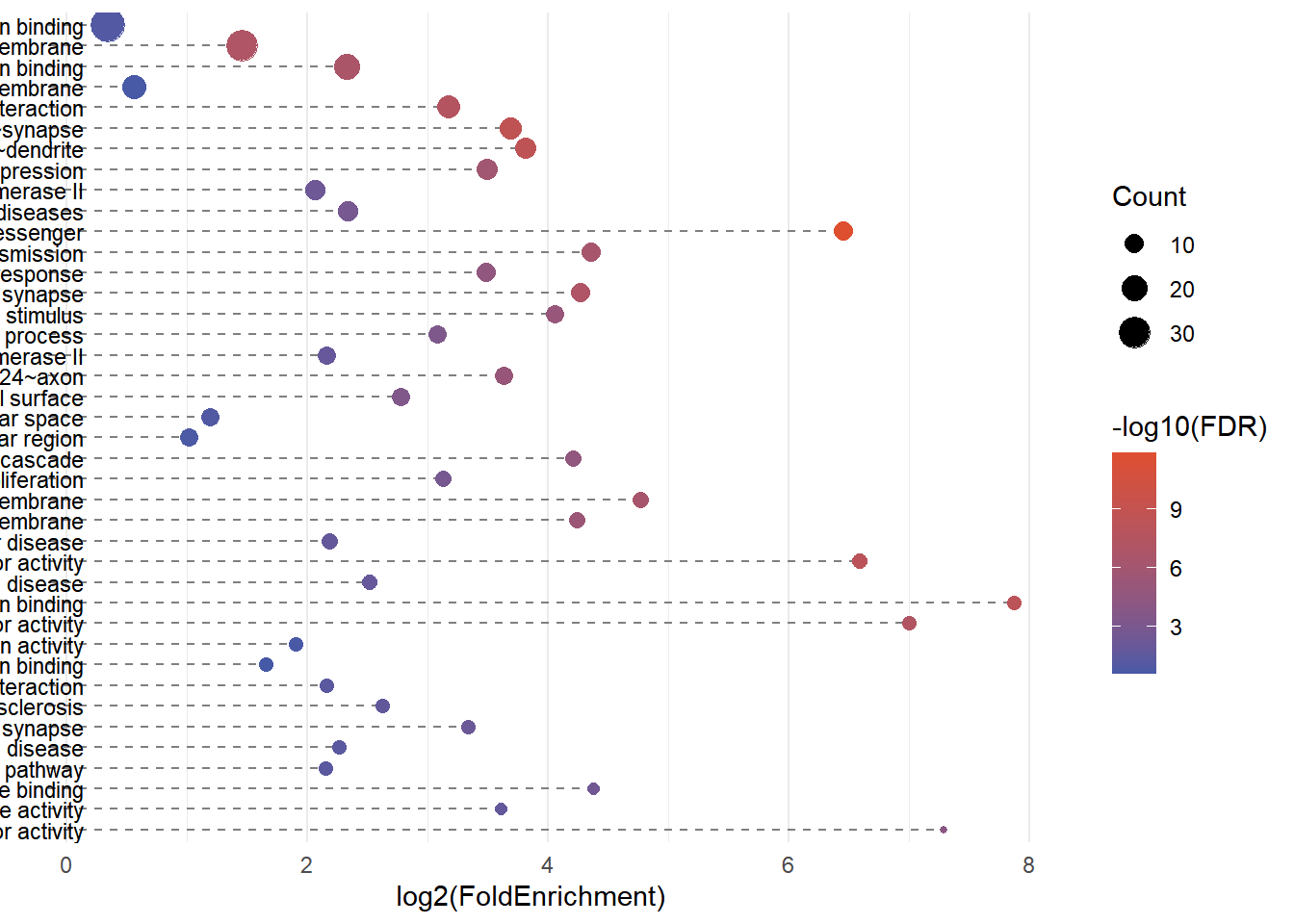
3. 拼接
combined_plot <- p1 + p2 + plot_layout(widths = c(1.5, 2), guides = "collect")
print(combined_plot)